
Java
下载
https://www.oracle.com/cn/java/technologies/downloads
反编译
Github:skylot/jadx: Dex to Java decompiler
安装
java21 需要自己生成jre文件夹
cd "D:\JAVA\jdk-21.0.9"
bin\jlink.exe --module-path jmods --add-modules java.desktop --output jre
环境变量
- JAVA_HOME:
D:\JAVA\jdk-21.0.9 - PATH
%JAVA_HOME%\bin
学习
计算机网络体系结构
TCP/IP层填入_|的地方相当于包含了左侧OSI模型,如TCP/IP应用层相当于OSI中:应用层+表示层+会话层
| OSI 模型 | TCP/IP 模型 | 功能 | 示例协议 | 网关解决方案 |
|---|---|---|---|---|
| 应用层 | 直接与用户进行交互,提供网络服务,如网页浏览器、电子邮件等。 | |||
| 表示层 | _| | 数据的格式化、转换、加密、压缩等处理,确保数据在发送方和接收方之间以可理解的格式进行交换。 | ||
| 会话层 | _| | 管理应用程序之间的通信会话的建立、维护和终止,保证数据交换有序且不丢失。 | ||
| 传输层 | 提供端到端的可靠数据传输,确保数据包的完整性和可靠传输。它处理数据的分段、重组、错误检测和流量控制。 | |||
| 网络层 | 处理逻辑寻址和路由,负责数据包的传输,定义了IP地址并决定数据包的转发路径。 | |||
| 数据链路层 | 负责在同一网络内的节点之间可靠地传输数据。它处理帧的传输、错误检测、纠正和流量控制。 | |||
| 物理层 | _| | 负责物理设备之间的比特流传输,处理电信号的传输、网络接口卡、光纤、电缆等硬件设备的操作。 |
几种分布式通信
| 技术 | 用法 | 区别 |
|---|---|---|
| RPC | 远程过程调用,直接调用远程方法 | 基于编程语言和框架,需要定义接口 |
| REST | Representational State Transfer | 使用HTTP协议,通过URL进行资源操作 |
| Dubbo | 开源的分布式服务框架,支持RPC通信 | 集成了负载均衡、服务注册、服务发现等功能 |
| HTTP | 超文本传输协议,常用于Web应用 | 无状态,通信基于请求-响应模式 |
| RMI | 远程方法调用,Java特定的RPC | 基于Java,支持对象的远程调用,仅支持从一个JVM到另一个JVM的调用。 |
类加载的三种方法
Class的装载包括3个步骤:加载(loading),连接(link),初始化(initialize)
加载:查询并加载类的二进制数据.class
连接:
1. 验证:确保被加载的类的正确性;
2. 准备:为类的静态变量分配内存,并将其初始化为默认值;
3. 解析:把类中的符号引用转化为直接引用
初始化:为类的静态变量赋予正确的初始值
1、由new关键字创建一个类的实例
例:Person person = new Person();
2、使用Class.forName()通过反射加载类型,并创建对象实例
例:Class clazz = Class.forName("com.entity.Person");
Object person =clazz.newInstance();
3、使用某个ClassLoader实例的loadClass()方法
通过该 ClassLoader 实例的 loadClass() 方法载入。应用程序可以通过继承 ClassLoader 实现自己的类装载器。
例:Class clazz = classLoader.loadClass("Person");
Object person =clazz.newInstance();
1 和 2 使用的类加载器是相同的,都是当前类加载器(即:this.getClass.getClassLoader)。
3 由用户指定类加载器。如果需要在当前类路径以外寻找类,则只能采用第3种方式。即第3种方式加载的类与当前类分属不同的命名空间。
1 是静态加载,2、3是动态加载
new关键字和newInstance()方法的区别:
- newInstance:弱类型,低效率,只能调用无参构造;
- new:强类型,相对高效,能调用任何Public构造。
这里有几个需要比较的地方:
1. 通过new关键字实例化类的对象和通过Class.forName()加载类是当前类加载器,即this.getClass.getClassLoader,只能在当前类路径或者导入的类路径下寻找类。而用指定的classLoader来加载类可以从当前路径外寻找类,这里的classLoader甚至可以用户自定义。
2. 我们知道类加载机制的三个过程主要是加载-->连接-->初始化。Class.forName()实际调用的是Class.forName(className,true,this.getClass.getClassLoader),第二个参数表示加载完后是否立即初始化,第三个参数即前文提到的表示是当前类加载器。classLoader.loadClass()实际调用的是classLoader.loadClass(className,false),第二个参数表示加载完成后是否连接,即用此方法加载类,加载完成后不会去初始化,而用Class.forName()加载类加载完成后可以被初始化。所以有些类如果加载完成后需要立即被初始化则必须使用Class.forName()。例如在加载数据库驱动时,一般用Class.forName("com.mysql.jdbc.Driver")。这是因为该驱动有一个在静态代码块中注册驱动的过程,所以需要被初始化。
**3. **有两个异常
静态加载类时出现的一般是NoClassDefFoundError。
动态加载类时出现的一般是ClassNotFoundException。
这两者经常被用来比较,其实区别很大。NoClassDefFoundError是错误,不方便被捕捉也不需要被捕捉,不应该尝试从error中恢复程序。他是由于在使用new关键字实例化类的对象时,在内存中找不到对象了,一般比较少见,在运行时发生,即编译时可以找到类运行时却找不到了。而ClassNotFoundException是异常,是可以被捕捉的,应该捕捉并处理尝试恢复程序。这是由于利用类名动态加载类的时候,在外存储器类路径下找不到该类或者其依赖的jar包,还有一个导致其的原因是在同一个包中同一个类被不同的类加载器加载了两遍。
反射获取Class的三个方式
MyClass.class不会做任何类的初始化工作,JVM会使用ClassLoader类加载器将类加载到内存中Class.forName(类的全限定名)会进行类的静态初始化工作。同样,类会被JVM加载到内存中new MyClass().getClass静态初始化和非静态初始化工作都会进行- 使用这三种方式任意一种最终在JVM加载到内存中都会是
内存地址相同的,原因是使用的同一个ClassLoader类加载器加载某个类
逻辑运算符
Java的运算符 - 逻辑运算符 主要有3个:逻辑与(&&),逻辑或(||),逻辑非(!)
| 运算符 | 名称 | 说明 | 示例 |
|---|---|---|---|
| && | 逻辑与 | 两边都为true,则为true,否则为false | 3>1 && 5!=4,结果为true |
| || | 逻辑或 | 有一边为true,则为true,否则为fasle | 2>1 || 5>100,结果为true |
| ! | 逻辑非 | 为true时,值为false,为false时,值为true | !(2<1),结果为true |
extends | super
数组
排序
冒泡排序:嵌套两次for循环,两两元素依次向数组尾端方向比较,每次遍历将最大/小元素“冒泡”到正确位置。
- 正序(从小到大,默认):依次比较相邻元素,每次将大元素交换到右边,第一轮循环结束后最大元素在数组尾端。
- 倒序(从大到小):依次比较相邻元素,每次将小元素交换到右边,第一轮循环结束后最小元素在数组尾端。
选择排序:每次遍历从未排序部分选出最小元素,与未排序部分的第一个元素交换位置。
插入排序:将数组分为已排序和未排序两部分,逐个将未排序元素插入到已排序部分的正确位置。
- 将
index[0]元素默认为已排序的部分,待插入数据为key = index[1],每次将key往左边依次比较,将比key大的元素后移,直到找到key的正确位置,将key插入在此index处。(说是插入,其实就是赋值到这里,因为比他大的元素都已经移到这个index的后面儿)
- 将
快速排序:
Lomuto 分区法(Lomuto Partition Scheme)
Hoare 分区法(Hoare Partition Scheme)
总结
| 排序算法 | 平均时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 冒泡排序 | O(n²) | O(1) | 稳定 |
| 选择排序 | O(n²) | O(1) | 不稳定 |
| 插入排序 | O(n²) | O(1) | 稳定 |
| 快速排序 | O(n log n) | O(log n) | 不稳定 |
| 归并排序 | O(n log n) | O(n) | 稳定 |
| 堆排序 | O(n log n) | O(1) | 不稳定 |
集合
Java 集合框架主要包含以下核心接口:
Collection 接口:这是单列集合的根接口,用于存储一系列元素。
- List 接口:有序、可重复的集合。
- Set 接口:无序、不可重复的集合。
- Queue 接口:队列,通常遵循先进先出 (FIFO) 原则。
Map 接口:这是双列集合的根接口,用于存储“键值对”(Key-Value)映射。Map 不属于 Collection 体系。
Collection
List接口(有序、可重复)
List 就像是一个动态数组,元素可以通过索引(下标)来访问。它允许存储重复的元素,并且存入顺序和取出顺序一致。
常用实现类:
- ArrayList:
- 底层结构:动态数组。
- 特点:查询速度快(因为数组支持随机访问),但增删速度慢(因为增删需要移动元素)。
- 适用场景:多用于查询,较少进行增删操作。
- LinkedList:
- 底层结构:双向链表。
- 特点:增删速度快(只需改变指针指向),但查询速度慢(需要从头或尾开始遍历)。
- 适用场景:多用于增删,较少进行查询。
- Vector:
- 说明:这是一个古老的类,与 ArrayList 类似,但是它是线程安全的(同步)。因为效率较低,现在已很少使用,被
CopyOnWriteArrayList或手动加锁的 ArrayList 替代。
- 说明:这是一个古老的类,与 ArrayList 类似,但是它是线程安全的(同步)。因为效率较低,现在已很少使用,被
Set接口(无序、不可重复)
Set 类似于数学上的“集合”,它不包含重复的元素。注意,Set 中的“无序”是指存入顺序和取出顺序可能不一致(具体看实现类)。
常用实现类:
- HashSet:
- 底层结构:基于
HashMap实现。 - 特点:无序、存取速度快。它根据对象的
hashCode()和equals()方法来判断元素是否重复。 - 注意:要保证存储的自定义对象不重复,必须重写
hashCode()和equals()方法。
- 底层结构:基于
- LinkedHashSet:
- 底层结构:哈希表 + 链表。(继承自
HashSet,其底层对应的是LinkedHashMap。) - 特点:它是 HashSet 的子类,在 HashSet 基础上维护了一个链表记录插入顺序。因此,它有序(插入顺序),且不允许重复。
- 底层结构:哈希表 + 链表。(继承自
- TreeSet:
- 底层结构:红黑树(一种自平衡二叉树)。(底层对应的是
TreeMap) - 特点:可以对元素进行排序(自然排序或自定义排序)。同样不允许重复。
- 注意:存储的对象必须实现
Comparable接口或在构造时传入Comparator比较器。
- 底层结构:红黑树(一种自平衡二叉树)。(底层对应的是
Queue(队列)
Queue 通常用于模拟队列数据结构,用于在处理之前保存元素。
常用实现类:
- LinkedList:LinkedList 实现了 Deque 接口(双端队列),所以也可以用作队列。
- PriorityQueue:优先级队列。元素按照优先级(通常是大小)进行排序,不是简单的先进先出。
- ArrayDeque:基于数组的双端队列,效率通常高于 Stack(栈)。
Map
Map 用于存储键值对。Key 是唯一的,Value 可以重复。Map 不能包含重复的 Key,每个 Key 最多只能映射到一个 Value。
常用实现类:
- HashMap:
- 底层结构:JDK 1.8 之前是数组 + 链表;JDK 1.8 及以后是数组 + 链表 + 红黑树。
- 特点:线程不安全,效率高。允许 null 键和 null 值。
- 原理:通过 Key 的 hashCode 定位存储位置。如果发生哈希冲突(位置相同),则使用链表(或红黑树)存储。
- Hashtable:
- 说明:古老的类,类似于 HashMap,但是是线程安全的。它不允许 null 键和 null 值。因为效率低,现在基本不再使用。
- ConcurrentHashMap:
- 说明:线程安全的高性能 HashMap。在并发环境下,它是首选。
- TreeMap:
- 底层结构:红黑树。
- 特点:根据 Key 进行排序。Key 必须实现
Comparable接口或传入Comparator。
- LinkedHashMap:
- 底层结构:哈希表 + 链表。
- 特点:在 HashMap 基础上,维护了一个双向链表,记录了插入顺序(或访问顺序),因此是有序的。
核心区别总结
| 特性 | List | Set | Map |
|---|---|---|---|
| 元素是否重复 | 允许 | 不允许 | Key 不允许,Value 允许 |
| 是否有序 | 有序 (索引顺序) | 大部分无序 (除 LinkedHashSet/TreeSet) | 无序 (除 LinkedHashMap/TreeMap) |
| 常用场景 | 存储常规数据列表 | 去重、集合运算 | 键值对映射、缓存、索引 |
遍历集合的常用方式
遍历 List:
- 普通
for循环(利用索引)。 - 增强型
for循环(foreach)。 - 迭代器 (
Iterator)。
- 普通
遍历 Set:
- 增强
for循环。 - 迭代器 (
Iterator)。
- 增强
遍历 Map:
keySet():获取所有 Key,遍历 Key 再通过get(key)获取 Value。entrySet():获取所有键值对对象,效率通常比keySet()高(推荐使用)。values():只获取所有的 Value。
面试题常考点
ArrayList 和 LinkedList 的区别?
- 答:底层数据结构不同(数组 vs 链表)。数组查询快、增删慢;链表增删快、查询慢。
HashMap 的底层原理?
- 答:JDK 1.8 中,HashMap 由数组+链表+红黑树组成。当链表长度超过 8 且数组长度超过 64 时,链表会转为红黑树以提高查
询效率。HashMap 使用哈希算法确定元素位置。
- 答:JDK 1.8 中,HashMap 由数组+链表+红黑树组成。当链表长度超过 8 且数组长度超过 64 时,链表会转为红黑树以提高查
HashSet 是如何保证元素不重复的?
- 答:HashSet 底层依赖 HashMap。添加元素时,先计算 hashCode,如果位置相同则调用
equals()方法比较。如果hashCode不同,则直接存入;如果相同且equals()返回 true,则视为重复,拒绝存入。
- 答:HashSet 底层依赖 HashMap。添加元素时,先计算 hashCode,如果位置相同则调用
线程安全
//对于List接口 两种方式
Collections.synchronizedList(new ArrayList<>());
CopyOnWriteArrayList<Object> objects = new CopyOnWriteArrayList<>();
//对于Set接口 两种方式
Collections.synchronizedSet(new HashSet<>());
CopyOnWriteArraySet<Object> objects1 = new CopyOnWriteArraySet<>();
//对于Map接口,HashTable和ConcurrentHashMap都是线程安全的
Collections.synchronizedMap(new HashMap<>());
// HashTable和ConcurrentHashMap都是线程安全的
CopyOnWriteArrayList
提示
java.util.concurrent 包下面的接口。
全称:Copy-On-Write ArrayList(写时复制数组列表)。
定义:
它是 ArrayList 的线程安全变体。与 Vector 或 Collections.synchronizedList 不同,它通过一种“写时复制” 的机制来实现线程安全。
核心原理:写时复制
顾名思义,就是当我们要修改这个集合(添加、删除、修改元素)时,不直接在原数组上操作,而是:
- 复制:先将原数组复制一份,创建一个新数组。
- 修改:在这个新数组上进行修改操作。
- 引用:修改完成后,将原数组的引用指向这个新数组。
为什么这样设计?
- 读操作无锁:因为原数组在写操作期间不会被修改(只是改引用),所以读取操作不需要加锁,性能极高。
- 写操作加锁:为了保证复制过程的原子性,写操作是加锁的(使用
ReentrantLock)。
适用场景:
- 读多写少:例如:事件通知系统、黑名单/白名单管理、配置中心缓存。
- 不适合:写操作非常频繁的场景,因为每次写都要复制数组,内存消耗大,性能差。
CopyOnWriteArraySet
提示
java.util.concurrent 包下面的接口。
全称:Copy-On-Write Array Set。
定义:
它是 Set 接口的线程安全实现,同样基于“写时复制”机制。它的底层完全依赖于 CopyOnWriteArrayList。
它们的关系和之前的 HashSet 与 HashMap 的关系非常相似。
一句话总结:CopyOnWriteArraySet 的底层就是封装了一个 CopyOnWriteArrayList。
- 源码层面的验证
如果你查看 CopyOnWriteArraySet 的源码,你会发现它内部维护了一个 CopyOnWriteArrayList 的对象:
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable {
// 内部就有一个 CopyOnWriteArrayList
private final CopyOnWriteArrayList<E> al;
// 构造函数
public CopyOnWriteArraySet() {
this.al = new CopyOnWriteArrayList<>();
}
}
- 操作是如何实现的?
由于 CopyOnWriteArraySet 底层是用 List 实现的,为了保证 Set 的特性(元素不可重复),它的所有操作都变成了对底层 List 的特殊调用:
添加元素 (
add):- 它不能直接调用
list.add(e),因为 List 允许重复。 - 它调用的是
list.addIfAbsent(e)(如果不存在则添加)。 addIfAbsent方法会遍历数组检查是否存在该元素,如果不存在才进行“写时复制”并添加。
- 它不能直接调用
删除/包含:
- 直接调用底层
CopyOnWriteArrayList对应的方法。
- 直接调用底层
- 两者对比总结
| 特性 | CopyOnWriteArrayList | CopyOnWriteArraySet |
|---|---|---|
| 数据结构 | 动态数组 (List) | 动态数组 (通过 List 模拟 Set) |
| 元素是否重复 | 允许重复 | 不允许重复 |
| 底层实现 | 独自实现了“写时复制”逻辑 | 直接持有 CopyOnWriteArrayList 对象 |
| 有序性 | 有序 (按插入顺序) | 有序 (按插入顺序) |
| 性能 | 写操作慢(需复制),读操作极快 | 写操作更慢 (需复制 + 遍历检查重复),读操作极快 |
总结
- CopyOnWriteArrayList 是基础实现者,它解决了多线程下安全遍历 ArrayList 的问题。
- CopyOnWriteArraySet 是“寄生”实现者,它复用了
CopyOnWriteArrayList的代码,只是在添加元素时多做了一步“去重”检查,从而变身为一个线程安全的 Set。
LocalDate
以下是 LocalDate 类的一些常用方法和参数的详细解释,以表格形式呈现:
| 方法 | 描述 | 参数 |
|---|---|---|
now() | 返回当前日期。 | 无 |
of(int year, int month, int dayOfMonth) | 返回指定年月日的日期。 | year - 年份,month - 月份,dayOfMonth - 日期 |
ofYearDay(int year, int dayOfYear) | 返回指定年份和年中的天数的日期。 | year - 年份,dayOfYear - 年中的天数 |
ofEpochDay(long epochDay) | 返回从 1970-01-01 起的指定天数后的日期。 | epochDay - 从 1970-01-01 起的天数 |
parse(CharSequence text) | 从字符串解析为 LocalDate。 | text - 要解析的字符串 |
getYear() | 返回年份。 | 无 |
getMonth() | 返回月份的枚举值。 | 无 |
getMonthValue() | 返回月份的数值(1-12)。 | 无 |
getDayOfMonth() | 返回月份中的日期。 | 无 |
getDayOfWeek() | 返回星期几的枚举值。 | 无 |
lengthOfMonth() | 返回当前月份的天数。 | 无 |
isLeapYear() | 判断是否是闰年。 | 无 |
plusYears(long years) | 返回增加指定年数后的日期。 | years - 增加的年数 |
plusMonths(long months) | 返回增加指定月数后的日期。 | months - 增加的月数 |
plusDays(long days) | 返回增加指定天数后的日期。 | days - 增加的天数 |
minusYears(long years) | 返回减少指定年数后的日期。 | years - 减少的年数 |
minusMonths(long months) | 返回减少指定月数后的日期。 | months - 减少的月数 |
minusDays(long days) | 返回减少指定天数后的日期。 | days - 减少的天数 |
isEqual(LocalDate other) | 判断是否与另一个日期相等。 | other - 另一个日期 |
isBefore(LocalDate other) | 判断是否在另一个日期之前。 | other - 另一个日期 |
isAfter(LocalDate other) | 判断是否在另一个日期之后。 | other - 另一个日期 |
toString() | 返回格式为"YYYY-MM-DD"的日期字符串表示。 | 无 |
BigDecimal
保留两位小数,并四舍五入
- 加减乘:
num1.setScale(2, RoundingMode.HALF_UP) - 除法:
num1.divide(num2, 2, RoundingMode.HALF_UP)
AOP
切面
切点
// @Pointcut("execution(public * com..*.*Controller.*(..))") // 切入点描述 这个是controller包的切入点
@Pointcut("@within(org.springframework.web.bind.annotation.RestController) || @annotation(org.springframework.web.bind.annotation.RestController)|| @within(org.springframework.stereotype.Controller) || @annotation(org.springframework.stereotype.Controller)")
public void xxxFun(){ //... }
- 使用 &&与、||或、!非 连接多个表达式
- execution:
- 使用
execution是一个方法级别的切点,用于可以匹配特定方法的执行。 - 示例:
@Pointcut("execution(* com.example.service.*.*(..))")匹配com.example.service包中所有类的所有方法。
- 使用
- @within:
@within是一个类型级别的切点,用于匹配包含 特定注解的类 及其 所有方法。- 示例:
@Pointcut("@within(org.springframework.stereotype.Service)")匹配所有被@Service注解标记的类及其所有方法。
git 仓库示例
aop-test: AOP测试项目,使用@Before模仿ruoyi进行数据权限查询 (gitee.com)
泛型
通配符
? super R 和 ? extends V 是 Java 泛型中的通配符表达式,用于表示类型的上界和下界。
? super R: 表示类型的下界。这意味着泛型参数可以是 R 或 R 的父类型。通常用于写入(添加)数据到泛型结构中。List<? super Integer> list = new ArrayList<>(); list.add(10); // 合法 list.add(20); // 合法 // 读取数据时需要进行类型转换 Object element = list.get(0);? extends V: 表示类型的上界。这意味着泛型参数可以是 V 或 V 的子类型。通常用于读取数据,而不是写入。List<? extends Number> list = new ArrayList<>(); Number number = list.get(0); // 合法 // 不能写入数据,因为编译器无法确定具体的子类型 // list.add(10); // 非法
这些通配符表达式在泛型编程中用于提供更灵活的类型约束。它们允许你编写泛型代码,适用于多种类型的参数,而不是固定在一个具体的类型上。在使用这些通配符时,你要根据具体的需求和语境来选择是使用下界还是上界。
总体而言:
? super R用于接受 R 或 R 的父类型,通常用于写入操作。? extends V用于接受 V 或 V 的子类型,通常用于读取操作。
public class Person{}
class Student extends Person{}
class Teacher extends Person{}
psvm(){
List<? super Student> list = new ArrayList<>();
list.add(new Teacher());
list.get(0);
List<? extends Person> list = new ArrayList<>();
Teacher t1 = (Teacher)list.get(0);
list.add(new Teacher()); // 报错
}
备注
以下代码是ruoyi-cloud里的一段代码:
com.ruoyi.common.redis.service.RedisService#getCacheObject
public <T> T getCacheObject(final String key)
{
ValueOperations<String, T> operation = redisTemplate.opsForValue();
return operation.get(key);
}
方法签名中的泛型: 泛型方法的签名中,<T> 是一个占位符,表示一种未知的类型。在实际调用方法时,类型参数 T 会被替换为实际的类型。例如:
// 这里 T 被替换为 Integer
Integer integerValue = getCacheObject("integerKey");
// 这里 T 被替换为 User
User user = getCacheObject("stringKey");
函数式编程
函数式接口
Stream
flatMap及Stream.of()、Stream.concat()的用法
List<Student> stuList = new ArrayList<>();
stuList.add(new Student("101", "Alice"));
stuList.add(new Student("102", "Bob"));
stuList.add(new Student("103", "John"));
/**
* 需求: Student里有很多属性,但我只需要其中的两个String类型的属性,将这两个属性放到一个Set<String>集合里
* 1.
* Stream.of() 方法是 java.util.stream.Stream 类中的一个静态方法,
* 它用于创建一个由指定元素构成的 Stream。该方法允许你在不依赖任何集合的情况下,
* 直接将指定的元素作为 Stream 进行处理。
* 2.
* 使用 Stream.concat() 方法来合并两个 Stream,而不是使用 Stream.of()。
* 这样,我们就可以把 name 和 rollNumber 分别作为两个不同的元素传入,然后将它们合并为一个 Stream。
*/
Set<String> nameAndRollNumberSet = stuList.stream()
.flatMap(student -> Stream.of(student.getStuId(), student.getStuName()))
.collect(Collectors.toSet());
Set<String> nameAndRollNumberSet2 = stuList.stream()
.flatMap(student -> Stream.concat(
Stream.of(student.getStuId()),
Stream.of(student.getStuName())))
.collect(Collectors.toSet());
// 输出结果
nameAndRollNumberSet.forEach(System.out::println);
System.out.println("----------------------------------");
nameAndRollNumberSet2.forEach(System.out::println);
flatMap() 解释
flatMap 是 Stream API 中的一个中间操作方法,它用于将多个 Stream 合并为一个 Stream。该方法接受一个函数作为参数,这个函数将每个元素转换为一个新的 Stream,然后将所有新 Stream 合并为一个结果 Stream。
方法签名如下:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
其中:
T是原始 Stream 的元素类型。R是新 Stream 的元素类型。mapper是一个函数,它将每个元素T转换为一个新的 Stream,这个函数的返回类型是Stream<? extends R>。
flatMap 方法的工作原理如下:
- 对于原始 Stream 中的每个元素,应用
mapper函数将其转换为一个新的 Stream。 - 将所有新的 Stream 合并为一个结果 Stream。
- 最终返回合并后的结果 Stream。
一般来说,flatMap 方法用于处理具有嵌套结构的数据。例如,一个 List 中包含了多个子列表,你可以使用 flatMap 方法将这些子列表合并为一个扁平化的 Stream。
示例:
假设有一个 List 包含多个子列表:
List<List<Integer>> listOfLists = List.of(
List.of(1, 2, 3),
List.of(4, 5),
List.of(6, 7, 8, 9)
);
你可以使用 flatMap 方法将这些子列表合并为一个扁平化的 Stream:
import java.util.List;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
List<List<Integer>> listOfLists = List.of(
List.of(1, 2, 3),
List.of(4, 5),
List.of(6, 7, 8, 9)
);
List<Integer> flattenedList = listOfLists.stream()
.flatMap(List::stream)
.collect(Collectors.toList());
System.out.println(flattenedList); // 输出结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]
}
}
在上述代码中,我们使用 flatMap 方法将 listOfLists 中的多个子列表转换为一个扁平化的 Stream。最终,通过 collect 方法将结果收集到一个 List<Integer> 中。输出结果是一个扁平化的列表,包含了所有原始子列表中的元素。
总结:
flatMap 方法是 Stream API 中用于合并多个 Stream 的重要方法。它在处理嵌套结构的数据时非常有用,可以将多个子集合并为一个扁平化的 Stream,简化数据处理过程。
示例
需求:有一个多个房间的账单汇总List,一个对象为一个房间,每个房间里又有一个账单明细List,现在需要将所有明细扁平化为一个List,要求首先依据房间名称正序排列,然后每个房间里的账单明细由endDate正序排序
// 查询到账单汇总表并将结果集依据房间名称正序排列
List<CaTalentApartmentContractBill> billList = billDao.findList(whereBillEntity)
.stream().sorted(Comparator.comparing(CaTalentApartmentContractBill::getRoomName))
.collect(Collectors.toList());
// 每个房间根据计租截止日期正序排列之后,返回为一个List
final List<CaTalentApartmentContractBillDetails> billDetailsList = billList
.stream()
.flatMap(bill -> bill
.getTalentApartmentContractBillDetailsList()
.stream()
.sorted(Comparator.comparing(CaTalentApartmentContractBillDetails::getEndDate))
)
.collect(Collectors.toList());
flatMapToInt, flatMapToLong, 和 flatMapToDouble
flatMapToInt, flatMapToLong, 和 flatMapToDouble 是 Stream API 中的特殊版本的 flatMap 方法。它们分别用于处理基本数据类型的 Stream(IntStream、LongStream 和 DoubleStream)。这些方法将 Stream 中的每个元素映射为一个基本数据类型的 Stream,然后将这些基本数据类型的 Stream 合并为一个结果 Stream。
这三个方法的工作原理类似于普通的 flatMap 方法,只不过它们处理的是基本数据类型而不是对象。由于它们返回的是基本数据类型的 Stream,因此在合并和处理过程中,避免了装箱和拆箱的开销,提高了性能。
以下是这三个方法的签名:
flatMapToInt方法:
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper)
flatMapToLong方法:
LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper)
flatMapToDouble方法:
DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper)
其中,T 是原始 Stream 的元素类型。
示例:
假设有一个 List 包含多个字符串,每个字符串是由逗号分隔的整数序列:
List<String> listOfStrings = List.of("1,2,3", "4,5", "6,7,8,9");
你可以使用 flatMapToInt 方法将每个字符串转换为一个 IntStream,然后将所有 IntStream 合并为一个结果 IntStream:
import java.util.List;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
List<String> listOfStrings = List.of("1,2,3", "4,5", "6,7,8,9");
IntStream flattenedIntStream = listOfStrings.stream()
.flatMapToInt(s -> {
String[] numbers = s.split(",");
return IntStream.of(numbers)
.mapToInt(Integer::parseInt);
});
flattenedIntStream.forEach(System.out::println); // 输出结果:1 2 3 4 5 6 7 8 9
}
}
在上述代码中,我们使用 flatMapToInt 方法将 listOfStrings 中的每个字符串转换为一个 IntStream,然后通过 flatMapToInt 的结果 IntStream 将所有字符串中的整数合并为一个结果 IntStream。最终,通过 forEach 方法输出结果。
类似地,你可以使用 flatMapToLong 和 flatMapToDouble 方法来处理 LongStream 和 DoubleStream。
总结:
flatMapToInt, flatMapToLong, 和 flatMapToDouble 是 Stream API 中用于处理基本数据类型的 Stream 的特殊版本的 flatMap 方法。它们将多个基本数据类型的 Stream 合并为一个结果 Stream,避免了装箱和拆箱的开销,提高了性能。
List里Date降序
// 对日期进行降序排序
List<MyObject> sortedList = list.stream()
.sorted(Comparator.comparing(MyObject::getDate).reversed())
.collect(Collectors.toList());
List只取日期最大的一个
- 1
final CaShopContractBillSettlement lastBill = billDao
.findList(whereShopContractBill)
.stream()
.max(Comparator.comparing(CaShopContractBillSettlement::getEndDate))
.orElse(null);
这段代码的作用是从数据库中查询一组符合条件的 CaShopContractBillSettlement 对象,然后通过流式操作找到具有最大结束日期(endDate)的对象。
让我解释一下每一步的含义:
billDao.findList(whereShopContractBill): 这是一个数据库查询操作,它使用billDao对象(可能是一个 DAO 或 Repository)调用findList方法,传入一个查询条件whereShopContractBill,返回了一组满足条件的CaShopContractBillSettlement对象。.stream(): 这将查询结果转换为一个流(Stream),使你可以使用流式操作对查询结果进行处理。.max(Comparator.comparing(CaShopContractBillSettlement::getEndDate)): 这一步使用流的max方法找到具有最大endDate的对象。Comparator.comparing(CaShopContractBillSettlement::getEndDate)创建了一个比较器,它根据endDate属性进行比较。然后,max方法根据这个比较器找到最大的对象。.orElse(null): 如果找到了最大的对象,则返回该对象;如果没有找到,则返回null。
所以,整个代码的目的是查询一组对象,并找到其中具有最大结束日期的对象。最后,如果找到了最大的对象,就返回该对象,否则返回 null。
- 2 对日期筛选之后进行取EndDate最大的一条
final CaShopContractBillSettlement lastBill = billSettlementDao
.findList(whereShopContractBill)
.stream()
.filter(bill -> !mainId.equals(bill.getReletId()))
.max(Comparator.comparing(CaShopContractBillSettlement::getEndDate))
.orElse(null);
groupingBy
关键字
final
- 当final修饰变量时,被修饰的变量必须被初始化(赋值),且后续不能修改其值,实质上是常量;
- 当final修饰方法时,被修饰的方法无法被所在类的子类重写(覆写);
- 当final修饰类时,被修饰的类不能被继承,并且final类中的所有成员方法都会被隐式地指定为final方法,但成员变量则不会变。
static
类变量,类方法,失去了多态,属于类所有,不用实例化就可以使用
MQ
意义
消息队列(MQ,Message Queue)的出现主要是为了解决分布式系统中异步通信、解耦合、提高系统可靠性、削峰填谷等问题。以下是一些项目中的实际需求,以及消息队列的应用场景和意义:
订单处理系统:
- 需求: 在一个高并发的电商平台上,用户提交订单后,系统需要处理订单、生成发货单、进行库存扣减等操作。
- MQ应用: 使用消息队列可以将订单处理流程异步化。当用户提交订单时,系统将订单信息放入消息队列中,后台服务从队列中取出订单,进行处理。这样能够降低用户等待时间,提高系统吞吐量,同时实现了系统模块的解耦。
日志处理系统:
- 需求: 在大规模的分布式系统中,需要对各个节点产生的日志进行集中处理、分析和存储。
- MQ应用: 使用消息队列可以异步地将日志信息发送到中央日志服务器。这样可以避免因为日志服务器故障或网络延迟导致整个系统的性能下降。通过消息队列,可以确保日志系统的稳定性和可扩展性。
通知和推送服务:
- 需求: 在社交网络或在线协作平台中,需要实时地向用户发送通知、消息或推送。
- MQ应用: 使用消息队列作为通知服务的基础设施,当有新消息需要推送时,系统将消息放入消息队列,推送服务异步地从队列中获取消息,并将通知发送给用户。这样可以提高通知的实时性,同时降低推送服务对系统的影响。
解耦合的微服务架构:
- 需求: 在微服务架构中,各个微服务之间需要进行通信,但不希望耦合度过高。
- MQ应用: 使用消息队列作为微服务之间的通信媒介,微服务通过发送和接收消息进行异步通信。这样每个微服务只需关注自己的业务逻辑,而不需要直接依赖其他微服务的实现。消息队列能够降低系统的复杂性,提高系统的可维护性和可扩展性。
任务队列和异步处理:
- 需求: 在某些业务场景中,需要执行一些耗时的任务,但不希望用户等待任务完成。
- MQ应用: 使用消息队列作为任务队列,当有任务需要执行时,系统将任务信息放入队列中,后台的工作节点异步地从队列中获取任务并执行。这样能够将任务的执行和用户请求解耦,提高系统的响应速度。
总的来说,消息队列的意义在于提供了一种高效、可靠的异步通信机制,帮助解决分布式系统中的通信、解耦、可靠性、削峰填谷等问题,从而提升整体系统的性能和可维护性。
动态代理
- 动态代理其实就是jdk运行期间,动态创建class字节码并加载到JVM
- JDK动态代理:生成新的类并,并且通过传入的
InvocationHandler处理方法调用。 - CGLib动态代理:生成目标类的,并包含了切面逻辑和对目标方法的调用。
- JDK动态代理:生成新的类并,并且通过传入的
JDK动态代理
JDK动态代理是Java动态代理的一种实现方式,它基于Java的反射机制和java.lang.reflect包,里面有三个类:InvocationHandler,Method,Proxy。在JDK动态代理中,代理类是在运行时动态生成的,而不是在编译时静态生成的。
以下是JDK动态代理的原理:
- 接口定义: 首先,你需要有一个接口,并定义实现类。它定义了代理类和目标类应该实现的共同接口。代理类将实现这个接口,并在其中添加横切逻辑。
public interface MyInterface {
void myMethod();
}
/*
public class MyImpl1 implements MyInterface {
@Override
public void myMethod() {
System.out.println("myImpl1");
}
}
*/
- InvocationHandler接口: 创建一个实现
InvocationHandler接口的类,该接口中有一个方法invoke,在代理对象上调用方法时将被调用。invoke方法接收三个参数:代理对象、方法对象和方法参数。在invoke方法中,你可以添加横切逻辑,然后通过反射调用目标对象的方法。
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class MyInvocationHandler implements InvocationHandler {
private Object target;
public MyInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 添加横切逻辑(例如日志记录、性能统计等)
System.out.println("Before method invocation");
// 调用目标对象的方法
Object result = method.invoke(target, args);
// 添加横切逻辑(例如日志记录、性能统计等)
System.out.println("After method invocation");
return result;
}
}
- 动态生成代理类: 使用
Proxy.newProxyInstance方法动态生成代理类。这个方法接收三个参数:类加载器(ClassLoader)、实现的接口数组和InvocationHandler对象。
import java.lang.reflect.Proxy;
public class Main {
public static void main(String[] args) {
// 创建目标对象
MyInterface targetObject = new MyTarget();
// 创建InvocationHandler对象
MyInvocationHandler invocationHandler = new MyInvocationHandler(targetObject);
// 动态生成代理类
MyInterface proxyObject = (MyInterface) Proxy.newProxyInstance(
targetObject.getClass().getClassLoader(),
targetObject.getClass().getInterfaces(),
invocationHandler
);
// 通过代理对象调用方法
proxyObject.myMethod();
}
}
- 调用代理类的方法: 当通过代理对象调用方法时,
invoke方法会被调用,并在其中执行横切逻辑,然后通过反射调用目标对象的方法。
在上述示例中,MyTarget是目标对象实现了MyInterface接口,MyInvocationHandler实现了InvocationHandler接口,而Main类演示了如何创建目标对象、创建代理对象并调用代理对象的方法。
JDK动态代理的优势在于不需要手动编写代理类,而是在运行时动态生成,从而更灵活地适应各种接口。但需要注意的是,JDK动态代理只能代理实现了接口的类,对于没有实现接口的类,可以考虑使用CGLIB等其他动态代理库。
CGlib动态代理
CGLIB(Code Generation Library) 介绍与原理 | 菜鸟教程 (runoob.com)
CGLIB(Code Generation Library)是一个基于ASM(Java字节码操作和分析框架)的代码生成库,它用于生成被代理类的子类。与JDK动态代理不同,CGLIB允许代理非接口类型的类。CGLib底层采用ASM字节码生成框架,使用字节码技术生成代理类,比使用Java反射效率要高。唯一需要注意的是,CGLib不能对声明为final的方法进行代理,因为CGLib原理是动态生成被代理类的子类。以下是CGLIB动态代理的简要原理:
- 实现MethodInterceptor接口: 创建一个实现
MethodInterceptor接口的类,该接口包含了一个intercept方法,用于在调用代理对象方法时添加横切逻辑。
import java.lang.reflect.Method;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class MyMethodInterceptor implements MethodInterceptor {
/**
* 重写方法拦截在方法前和方法后加入业务
* @param obj 目标对象(由CGLib动态生成的代理类实例)
* @param method 目标方法(上文中实体类所调用的被代理的方法引用)
* @param params 参数值列表
* @param proxy CGlib方法代理对象(生成的代理类对方法的代理引用)
*/
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
// 添加横切逻辑(例如日志记录、性能统计等)
System.out.println("Before method invocation");
// 调用目标对象的方法
Object result = proxy.invokeSuper(obj, args);
// 添加横切逻辑(例如日志记录、性能统计等)
System.out.println("After method invocation");
return result;
}
}
- 创建Enhancer对象: 在CGLIB中,代理类是通过
Enhancer类创建的。Enhancer是CGLIB的主要类,是CGLib中的一个字节码增强器,它可以方便的对你想要处理的类进行扩展。用于创建代理对象。
Enhancer enhancer = new Enhancer();
- 设置被代理类和回调对象: 使用
Enhancer对象的setSuperclass方法设置父类为被代理类,使用setCallback方法设置回调对象。回调对象是一个实现了MethodInterceptor接口的类,它负责拦截被代理类的方法调用。
// MyClass 是一个自己定义一个类,该类没有实现任何接口。
enhancer.setSuperclass(MyClass.class);
enhancer.setCallback(new MyMethodInterceptor());
- 创建代理类: 调用
Enhancer对象的create方法生成代理对象。这个代理对象是被代理类的子类,它继承了被代理类的所有非final方法,并在这些方法中调用了MethodInterceptor的intercept方法。
MyClass proxyObject = (MyClass) enhancer.create();
- 调用代理类的方法: 当通过代理对象调用方法时,代理类中的方法会被拦截,
MethodInterceptor的intercept方法会被执行,其中可以添加横切逻辑,并通过MethodProxy对象调用目标对象的方法。
proxyObject.myMethod();
总体来说,CGLIB动态代理的原理是通过生成被代理类的子类,并在子类中添加横切逻辑,从而实现对被代理类的代理。这个子类继承自被代理类,因此可以覆盖被代理类的非final方法,并在这些方法中调用MethodInterceptor的intercept方法,实现对目标对象方法的拦截。
代码块
动态代码块
在java类中使用{}声明的代码块,也称构造代码块(和静态代码块的区别是少了static关键字)
构造代码块在创建对象时被调用,每次创建对象都会调用一次,但是优先于构造函数执行(依托于构造函数)。
静态代码块
在java类中使用static {} 声明的代码块。静态块用于初始化类,为类的属性初始化。每个静态代码块只会执行一次。静态代码块随着类加载而加载,有多个静态代码块的,按代码块前后顺序加载。由于JVM在加载类时会执行静态代码块,所以静态代码块先于主方法、各种代码块、构造函数执行。如果有些代码需要在项目启动的时候就执行,这时候就需要静态代码块。
带参数的try
带资源的try语句(try-with-resource)的最简形式为
//可指定多个资源
try(Resource res = xxx) {
work with res
}
try块退出时,会自动调用res.close()方法,关闭资源。
示例:
InputStream is = null;
OutputStream os = null;
try {
//...
} catch (IOException e) {
//...
}finally{
try {
if(os!=null){
os.close();
}
if(is!=null){
is.close();
}
} catch (IOException e2) {
//...
}
}
现在就可以写为:
try(
InputStream is = new FileInputStream("...");
OutputStream os = new FileOutputStream("...");
){
//...
}catch (IOException e) {
//...
}
(生活一下就美好了)
设计模式
单例模式
静态类内部加载
public class SingletonDemo {
private static class SingletonHolder{
private static SingletonDemo instance=new SingletonDemo();
}
private SingletonDemo(){
System.out.println("Singleton has loaded");
}
public static SingletonDemo getInstance(){
return SingletonHolder.instance;
}
}
这种基于静态内部类的单例模式实现方式是线程安全的,主要得益于 Java 类加载机制的特性:
类加载时机: 静态内部类
SingletonHolder只有在第一次被调用的时候才会被加载。这保证了SingletonHolder类的加载是懒加载的,只有在需要获取单例实例时才会加载。类加载的线程安全性: Java 的类加载是线程安全的。当多个线程同时尝试加载同一个类时,JVM 会保证只有一个线程加载并初始化该类,其他线程会等待。这确保了静态内部类
SingletonHolder的加载是线程安全的。类加载过程的原子性: 类加载过程是原子的,包括类的加载、连接(验证、准备、解析)、初始化等步骤。在类加载过程中,JVM 会对类进行初始化,确保只有一个线程执行初始化过程。这进一步确保了对静态内部类
SingletonHolder的初始化是原子的,从而保证了线程安全性。
综上所述,由于静态内部类的加载是线程安全的,且其初始化过程是原子的,因此在这种实现方式下,获取单例实例的操作是线程安全的。即使在多线程环境中,也不会出现多个线程同时创建多个实例的情况。这种实现方式既实现了懒加载,又保证了线程安全性,是一种常见的单例模式实现方式。
枚举方法
在Java中,使用枚举(Enum)来实现单例模式是一种简洁、高效且线程安全的方式。枚举类的每个枚举常量都是单例的,而且在枚举类型加载时就被实例化,保证了线程安全性。
以下是使用枚举实现单例模式的例子:
public enum SingletonEnum {
INSTANCE;
// 在枚举中可以添加其他方法和成员变量
public void someMethod() {
System.out.println("Some method of SingletonEnum");
}
}
在上面的例子中,SingletonEnum 是一个枚举类型,它有一个名为 INSTANCE 的枚举常量,这个常量就是单例的实例。
使用方式:
public class Main {
public static void main(String[] args) {
// 获取单例实例
SingletonEnum singleton = SingletonEnum.INSTANCE;
// 使用单例方法
singleton.someMethod();
}
}
这种方式具有以下特点:
线程安全: 枚举在Java中是线程安全的,枚举常量在类加载时就被实例化,而且JVM会保证其只被实例化一次。
懒加载: 枚举在需要时才会被加载,因此具备懒加载的特性。
防止反序列化重新创建对象: 枚举类默认实现了
Serializable接口,枚举对象在被反序列化时会被还原为相应的枚举常量,这可以防止反序列化重新创建对象,从而保证单例的唯一性。
总体来说,使用枚举实现单例模式是一种推荐的方式,简单、安全、且易于理解。
IO流
以下是使用 Markdown 表格格式整理的 Java I/O 流的主要分类、作用以及主要方法:
字节流(Byte Streams)
| 类别 | 类名 | 作用 | 主要方法 |
|---|---|---|---|
| 输入流 | InputStream | 从输入源读取字节数据 | int read() throws IOExceptionint read(byte[] b) throws IOException |
| 输出流 | OutputStream | 向输出目标写入字节数据 | void write(int b) throws IOExceptionvoid write(byte[] b) throws IOException |
| 文件输入流 | FileInputStream | 从文件系统中的文件读取字节 | 构造方法:FileInputStream(String name)FileInputStream(File file)int available() |
| 文件输出流 | FileOutputStream | 将字节写入文件 | 构造方法:FileOutputStream(String name)FileOutputStream(File file)void flush() |
| 缓冲输入流 | BufferedInputStream | 提供缓冲功能,提高读取效率 | 构造方法:BufferedInputStream(InputStream in)int read(byte[] b, int off, int len) |
| 缓冲输出流 | BufferedOutputStream | 提供缓冲功能,提高写入效率 | 构造方法:BufferedOutputStream(OutputStream out)void write(byte[] b, int off, int len) |
字符流(Character Streams)
| 类别 | 类名 | 作用 | 主要方法 |
|---|---|---|---|
| 输入流 | Reader | 从输入源读取字符数据 | int read() throws IOExceptionint read(char[] cbuf) throws IOException |
| 输出流 | Writer | 向输出目标写入字符数据 | void write(int c) throws IOExceptionvoid write(char[] cbuf) throws IOException |
| 文件输入流 | FileReader | 从文件系统中的文件读取字符 | 构造方法:FileReader(String fileName)FileReader(File file) |
| 文件输出流 | FileWriter | 将字符写入文件 | 构造方法:FileWriter(String fileName)FileWriter(File file) |
| 缓冲输入流 | BufferedReader | 提供缓冲功能,提高读取效率 | 构造方法:BufferedReader(Reader in)String readLine() |
| 缓冲输出流 | BufferedWriter | 提供缓冲功能,提高写入效率 | 构造方法:BufferedWriter(Writer out)void newLine() |
字节字符转换流
| 类别 | 类名 | 作用 | 主要方法 |
|---|---|---|---|
| 字节转字符输入流 | InputStreamReader | 将字节流转换为字符流 | 构造方法:InputStreamReader(InputStream in)InputStreamReader(InputStream in, String charsetName) |
| 字节转字符输出流 | OutputStreamWriter | 将字符流转换为字节流 | 构造方法:OutputStreamWriter(OutputStream out)OutputStreamWriter(OutputStream out, String charsetName) |
其他
| 类别 | 类名 | 作用 | 主要方法 |
|---|---|---|---|
| 数据输入流 | DataInputStream | 读取基本数据类型 | 构造方法:DataInputStream(InputStream in)int readInt() |
| 数据输出流 | DataOutputStream | 写入基本数据类型 | 构造方法:DataOutputStream(OutputStream out)void writeInt(int v) |
| 对象输入流 | ObjectInputStream | 读取对象 | 构造方法:ObjectInputStream(InputStream in)Object readObject() |
| 对象输出流 | ObjectOutputStream | 写入对象 | 构造方法:ObjectOutputStream(OutputStream out)void writeObject(Object obj) |
多线程
Java 中的多线程开发是指在程序中同时执行多个任务,从而提高应用程序的效率和响应速度。以下是一些常见的多线程问题和解答:
创建
- 如何创建线程?
Java 提供了两种常见的方式来创建线程:
方式一:继承 Thread 类
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread is running");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start(); // 启动线程
}
}
方式二:实现 Runnable 接口
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Runnable is running");
}
}
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start(); // 启动线程
}
}
start()和run()方法有什么区别?
start()方法启动一个新线程,由 JVM 安排调用线程的run()方法,真正开始并行执行任务。- 直接调用
run()方法并不会启动新线程,只会在当前线程中执行run()方法。
示例:
public class Main {
public static void main(String[] args) {
Thread t = new Thread(() -> System.out.println("Thread running"));
t.run(); // 不会启动新线程,只是在主线程中执行
t.start(); // 启动新线程
}
}
- 线程的生命周期有哪些阶段?
Java 线程的生命周期可以分为以下几个阶段:
- New(新建):线程对象已创建,但未启动。
- Runnable(可运行):线程已经启动,等待 CPU 时间片来运行。
- Running(运行中):线程正在执行其任务。
- Blocked(阻塞):线程在等待锁或者 IO 操作,暂时无法执行。
- Terminated(终止):线程任务执行完成或遇到异常,线程终止。
- 如何停止线程?
- Java 不推荐使用
Thread.stop()方法来强制终止线程,因为它不安全。推荐使用标志位控制线程的终止。
示例:
class MyRunnable implements Runnable {
private volatile boolean running = true;
@Override
public void run() {
while (running) {
System.out.println("Thread is running");
}
}
public void stopRunning() {
running = false;
}
}
public class Main {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
// 停止线程
myRunnable.stopRunning();
}
}
- 如何使用线程同步?
线程同步是防止多个线程同时访问共享资源而导致数据不一致的关键。
使用 synchronized 关键字
synchronized 关键字可以用在方法或代码块中,确保同一时刻只有一个线程访问。
示例:
class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
}
public class Main {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Runnable runnable = () -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();
t2.start();
t1.join(); // 等待线程结束
t2.join();
System.out.println("Final Count: " + counter.getCount());
}
}
- 死锁问题及其避免
死锁 是指两个或多个线程相互等待对方释放资源,导致程序无法继续执行。常见的死锁场景是两个线程各自持有对方需要的锁。
避免死锁:
- 尽量减少持有锁的时间。
- 遵循固定的锁获取顺序,避免交叉锁定资源。
示例(避免死锁):
class A {
public synchronized void methodA(B b) {
System.out.println("Thread 1: Holding lock on A");
try { Thread.sleep(100); } catch (InterruptedException e) {}
System.out.println("Thread 1: Waiting for lock on B");
b.methodB();
}
public synchronized void methodB() {
System.out.println("In method B of A");
}
}
class B {
public synchronized void methodA(A a) {
System.out.println("Thread 2: Holding lock on B");
try { Thread.sleep(100); } catch (InterruptedException e) {}
System.out.println("Thread 2: Waiting for lock on A");
a.methodB();
}
public synchronized void methodB() {
System.out.println("In method B of B");
}
}
public class Main {
public static void main(String[] args) {
A a = new A();
B b = new B();
Thread t1 = new Thread(() -> a.methodA(b));
Thread t2 = new Thread(() -> b.methodA(a));
t1.start();
t2.start();
}
}
上例展示了可能引发死锁的情况。如果按顺序避免交叉锁定(即让所有线程以相同的顺序获取锁),就能避免死锁。
- 线程池的使用
线程池可以有效管理和复用线程资源,减少线程创建和销毁的开销。
使用 ExecutorService:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
Runnable task = () -> System.out.println("Task executed");
executor.submit(task);
executor.shutdown(); // 关闭线程池
}
}
wait()、notify()和notifyAll()的使用
wait() 和 notify() 方法用于线程间的协调。
wait():当前线程释放锁并进入等待状态,直到被notify()唤醒。notify():唤醒等待中的某一个线程。notifyAll():唤醒等待中的所有线程。
class Data {
private boolean flag = false;
public synchronized void produce() throws InterruptedException {
while (flag) {
wait(); // 等待消费
}
System.out.println("Produced");
flag = true;
notify(); // 通知消费者
}
public synchronized void consume() throws InterruptedException {
while (!flag) {
wait(); // 等待生产
}
System.out.println("Consumed");
flag = false;
notify(); // 通知生产者
}
}
public class Main {
public static void main(String[] args) {
Data data = new Data();
Thread producer = new Thread(() -> {
try {
while (true) {
data.produce();
}
} catch (InterruptedException e) { e.printStackTrace(); }
});
Thread consumer = new Thread(() -> {
try {
while (true) {
data.consume();
}
} catch (InterruptedException e) { e.printStackTrace(); }
});
producer.start();
consumer.start();
}
}
线程安全
同步代码块 和 同步方法 都使用锁机制来确保同一时刻只有一个线程能够访问共享资源,以下是加锁的粒度的不同。
同步代码块
(Synchronized Block)
用法:
同步代码块是将一段特定的代码用 synchronized 关键字包裹起来,这段代码需要锁住一个对象,以确保同一时刻只有一个线程可以执行它。
class Counter {
private int count = 0;
public void increment() {
// 使用 synchronized 块对某个对象进行加锁
synchronized (this) {
count++;
}
}
public int getCount() {
return count;
}
}
在上面的代码中,synchronized(this) 表示当前线程必须获得当前对象 this 的锁才能执行同步代码块中的代码。其他线程在同一时刻无法执行这段代码,直到当前线程释放锁。
加锁机制:
- 锁定对象(如
this或其他对象),在同一时刻只能有一个线程获得该对象的锁。 - 锁的粒度更小,仅同步需要保护的代码片段,这样可以减少锁的竞争,提升并发性能。
同步方法
(Synchronized Method)
用法:
同步方法是直接将整个方法用 synchronized 关键字修饰,这样一旦有一个线程调用这个方法,其他线程就必须等待,直到该线程执行完毕并释放锁。
class Counter {
private int count = 0;
// 使用 synchronized 修饰整个方法
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
在这个例子中,increment() 和 getCount() 都是同步方法。每次调用 increment() 时,线程会获得当前对象(this)的锁,其他线程无法调用这个同步方法,直到当前线程执行完并释放锁。
加锁机制:
- 锁定整个方法,意味着在同一时刻只能有一个线程访问该同步方法。
- 锁定的是 当前对象实例,即
this。如果是静态同步方法,则锁定的是 类对象(Class),不同实例的对象也会互相排队。
同步代码块与同步方法的加锁区别
锁的粒度不同
同步方法:整个方法都被锁住了,锁的粒度较大,无论方法内有多少代码,线程都必须等待方法执行完才能释放锁。
同步代码块:只对某些关键代码片段加锁,锁的粒度较小。通常使用同步代码块可以提高并发性能,因为其他线程可以同时执行未被锁定的代码。
锁的对象不同
- 同步方法:
- :锁定当前对象(
this)。 - :锁定当前类的
Class对象,即ClassName.class。
- :锁定当前对象(
- 同步代码块:可以选择加锁的对象,不仅限于
this,可以是任何对象(如其他共享资源、Class对象等)。灵活性更强。
- 同步方法:
性能差异
同步方法:锁定整个方法,意味着可能会锁住不必要的代码,造成性能开销较大,尤其当方法内有非关键代码段时。
同步代码块:锁定特定的代码块,限制性更强。只有真正需要同步的部分才会被加锁,其他代码可以并发执行,从而提升性能。
总结
| 特性 | 同步代码块 | 同步方法 |
|---|---|---|
| 锁定范围 | 代码块中的部分代码 | 整个方法 |
| 锁的粒度 | 粒度更小,更精细 | 粒度较大,整个方法都被锁 |
| 锁定对象 | 任意对象(this,自定义对象,类对象) | 非静态方法锁 this,静态方法锁类对象 |
| 并发性能 | 性能更高,锁的代码少 | 性能稍低,锁住整个方法 |
| 使用场景 | 需要同步部分代码时使用 | 整个方法都需要同步时使用 |
- 扩展
this关键字表示 当前实例对象,即正在调用非静态方法的那个对象。Counter c1 = new Counter(); Counter c2 = new Counter(); // 两个线程访问不同实例的同步方法,不会互相阻塞 Thread t1 = new Thread(() -> c1.increment()); Thread t2 = new Thread(() -> c2.increment());类锁 表示锁定的是 整个类
Counter c1 = new Counter(); Counter c2 = new Counter(); // 两个线程访问不同实例的静态同步方法,会互相阻塞 Thread t1 = new Thread(() -> Counter.incrementStatic()); Thread t2 = new Thread(() -> Counter.incrementStatic());
分布式
分布式事务的调用
- 远程过程调用(RPC):使用RPC,服务可以像本地调用一样调用远程服务。RPC框架提供了透明的远程调用接口,隐藏了网络通信的复杂性,例如gRPC、Apache Dubbo等。
- 消息队列:通过消息队列实现异步通信,将调用请求以消息的形式发送到队列中,另一个服务可异步地从队列中接收并处理消息。
- RESTful API:采用基于HTTP的RESTful API进行分布式调用,服务通过HTTP协议进行通信,使用标准的HTTP方法和数据格式进行数据交换。
- 服务网关:API网关可以提供服务注册与发现、负载均衡、安全认证等功能,便于服务之间的通信和调用。
- 分布式事务:采用分布式事务处理机制来保证多个服务之间的数据一致性和事务的隔离性。
几种密码加密方式🔑
- 强散列哈希加密(适应性哈希算法)spring-security-crypto(使用BCryptPasswordEncoder.encode())
- 若依实现方式:若依微服务版本-认证授权(ruoyi-auth)博客园
身份认证🔐
aka-登录认证
Spring Security,JWT(JSON Web Token),Session
【项目实践】一文带你搞定Session和JWT的登录认证方式 - RudeCrab - 博客园 (cnblogs.com)
鉴权 5 兄弟:cookie、session、token、jwt、单点登录,终于有人说清楚了! - Java技术栈 - 博客园 (cnblogs.com)
jsessionid是什么?cookie session 终于明白了 - Timeouting - 博客园 (cnblogs.com)
用户登录认证和权限授权(SpringSecurity、JWT、session)_(2)session来保存登录信息的方式,选用了springsecurity和jwt实现用户的登录和-CSDN博客
session和jwt登录认证时,java的拦截器和过滤器的作用分别是什么
ChatGPT
在Java Web开发中,无论是使用Session还是JWT(JSON Web Token)进行登录认证,拦截器(Interceptor)和过滤器(Filter)都是常见的用于实现请求拦截和处理的组件,它们的作用如下所示:
过滤器(Filter)
适用于对所有请求进行统一处理的场景
过滤器是Servlet规范中的一部分,用于对请求和响应进行预处理和后处理。主要作用包括:
- 请求处理前的预处理:
- 可以在请求到达Servlet之前进行一些预处理,如日志记录、字符编码转换等。
- 在认证方面,过滤器可以用于验证JWT的合法性。在JWT认证流程中,过滤器可以拦截请求,从请求中提取JWT Token,验证其签名和有效期,并根据验证结果决定是否允许请求继续访问资源。
- 响应处理后的后处理:
- 可以在响应返回给客户端之前进行一些后处理,如添加响应头、响应数据加工等。
- 主要适用场景:
- 过滤器通常用于请求级别的拦截处理,如安全过滤、日志记录、跨域处理、编码设置等。
- 在传统的Session认证中,过滤器可以用于检查用户的登录状态,如检查Session是否存在或有效,以决定是否允许访问受保护的资源。
// 匹配所有拦截请求
@WebFilter(urlPatterns = "/*")
public class MyFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
// 在这里可以处理请求或响应
HttpServletRequest req = (HttpServletRequest) request;
System.out.println("Request URI: " + req.getRequestURI());
// 继续请求链
chain.doFilter(request, response);
}
}
拦截器(Interceptor)
适合对部分特定接口做处理使用
拦截器是Spring框架提供的一种切面编程的方式,用于对处理器方法的调用进行拦截和处理。主要作用包括:
- 对Controller方法的调用前后进行拦截:
- 可以在Controller方法执行前后进行一些自定义的处理,如权限校验、日志记录、性能监控等。
- 在认证方面,拦截器可以拦截请求,进行JWT的解析和验证,并根据验证结果决定是否允许请求继续访问资源。
- 与Spring MVC集成紧密:
- 拦截器是Spring MVC框架的一部分,可以与其它Spring特性(如依赖注入)无缝集成。
- 主要适用场景:
- 拦截器通常用于对Controller层的方法进行拦截处理,如全局异常处理、登录拦截、参数预处理等。
- 身份认证、权限验证、请求参数的预处理
- 在JWT认证流程中,拦截器可以更好地与Spring框架集成,实现统一的认证和授权管理。
public class MyInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 在处理器方法调用之前调用
System.out.println("Pre Handle method is Calling");
return true; // 返回true才会继续执行链
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
// 在处理器方法调用之后但在视图渲染之前调用
System.out.println("Post Handle method is Calling");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 在整个请求完成之后,即视图渲染完成之后调用
System.out.println("Request and Response is completed");
}
}
区别总结
- 功能差异: 过滤器是Servlet规范的一部分,主要用于请求的预处理和后处理;拦截器是Spring框架的一部分,用于Controller方法的拦截和处理。
- 应用场景: 过滤器适用于请求级别的处理,如安全过滤、跨域处理;拦截器适用于对Controller方法的调用进行拦截处理,如权限校验、日志记录。
- 技术依赖: 过滤器在Servlet容器中执行,与具体的Servlet容器相关;拦截器在Spring容器中执行,与Spring框架集成更紧密。
在实际项目中,通常会根据具体的需求和技术栈选择使用过滤器或者拦截器来实现登录认证、权限控制等功能。
过滤器是Servlet规范中的一部分
Servlet规范的其他部分都有什么,各自有什么作用
ChatGPT
Servlet规范(Java Servlet API)定义了一系列接口和类,用于在Java Web应用程序中处理HTTP请求和响应。除了过滤器(Filter)之外,还有一些其他重要的部分,它们各自有不同的作用和功能。以下是Servlet规范中的一些主要部分及其作用:
- Servlet接口及相关类:
javax.servlet.Servlet接口及其实现类,如javax.servlet.http.HttpServlet,用于处理HTTP请求和响应。- Servlet 是处理客户端请求的Java类,它们可以接收来自Web服务器的请求并生成响应。
- Servlet容器:
- Servlet 容器是Web服务器或者Servlet引擎,负责管理和调用Servlet的生命周期、多线程支持、请求分发等功能。常见的Servlet容器有Apache Tomcat、Jetty、Undertow等。
- 会话管理(Session Management):
- Servlet规范提供了会话管理的支持,通过
javax.servlet.http.HttpSession接口来管理用户会话状态。会话可以在多个HTTP请求之间保持状态信息,用于跟踪用户的登录状态等。
- Servlet规范提供了会话管理的支持,通过
- 监听器(Listener):
javax.servlet.ServletContextListener和javax.servlet.http.HttpSessionListener等接口,用于监听Servlet上下文和会话的生命周期事件,允许开发人员在特定事件发生时执行自定义的操作。
- 过滤器(Filter):
javax.servlet.Filter接口及其实现类,用于在请求进入Servlet之前或响应离开Servlet之前对请求和响应进行预处理和后处理。常用于实现安全过滤、日志记录、字符编码转换等功能。
- 异步处理(Asynchronous Processing):
- Servlet 3.0规范引入了异步处理能力,允许Servlet在处理请求时进行异步操作,提高服务器的吞吐量和性能。
- URL映射和调度(URL Mapping and Dispatching):
- Servlet规范定义了如何根据URL将请求分派给适当的Servlet处理,并支持URL模式匹配和路径参数传递。
- 安全性(Security):
- Servlet规范也包含了一些安全相关的功能和接口,如基于角色的访问控制(Role-Based Access Control,RBAC)等。
这些部分共同构成了Java Web应用程序的核心组成部分,Servlet规范提供了一套标准的API和约定,使得开发人员可以编写可移植、可扩展和可维护的Web应用程序。
Session认证机制详解
使用过滤器实现
参考代码:身份认证:Session/JWT - Gitee.com
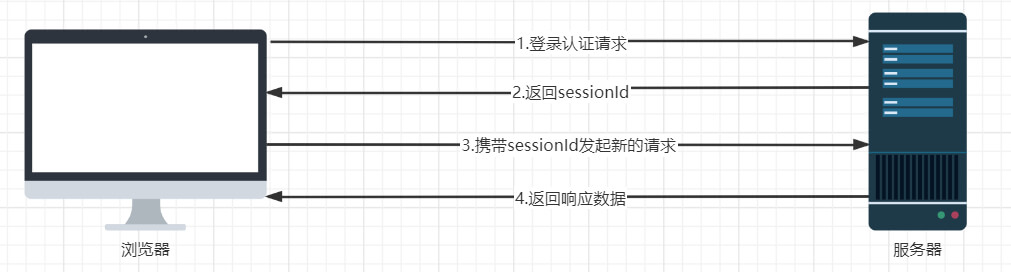
Session认证机制是一种常见的Web应用用户身份认证和会话管理方式,使用服务器端的会话(Session)对象来跟踪用户的登录状态和相关信息。以下是Session认证机制的详细讲解,包括其原理、实现、管理和安全性。
1. 基本工作原理
登录过程
用户登录请求:
- 用户在登录页面输入用户名和密码,并提交登录表单。
服务器验证:
- 服务器接收到登录请求后,验证用户名和密码的正确性(通常是通过查询数据库)。
创建Session(自动):
- 验证成功后,服务器创建一个新的Session对象,用于存储用户的会话信息。
- 服务器生成一个唯一的Session ID,并将其与创建的Session对象关联。(自动,不需要自己写实现)
- 通过
session.setAttribute("", xx)来绑定用户信息用于后续请求的身份认证。
返回Session ID(自动):
服务器将Session ID通过HTTP响应头中的
Set-Cookie:JSESSIONID=xxx字段发送给客户端。客户端浏览器将Session ID存储在Cookie中。
后续请求
携带Session ID:
- 客户端在后续的每次HTTP请求中会自动携带该Session ID(通过Cookie)。
服务器识别:
- 服务器通过请求中的
JSESSIONID找到对应的Session对象,从而识别用户session.getAttribute("")并获取其状态信息。
- 服务器通过请求中的
用户登出
用户请求登出:
- 用户请求登出时,服务器会使对应的Session失效。
清除会话数据:
- 服务器清除会话数据,并告知客户端删除存储的Session ID。
Session销毁只能通过invalidate或超时。关掉浏览器并不会清除Session,但浏览器可能会丢失Cookie,进而丢失JSESSIONID
2. 详细实现
登录请求处理示例
@PostMapping("/login")
public String login(@RequestParam String username, @RequestParam String password, HttpServletRequest request) {
// 验证用户名和密码
if (isValidUser(username, password)) {
// 创建新会话
HttpSession session = request.getSession(true);
session.setAttribute("username", username);
return "redirect:/home";
} else {
return "login";
}
}
后续请求处理示例
@GetMapping("/home")
public String home(HttpServletRequest request, Model model) {
HttpSession session = request.getSession(false);
if (session != null && session.getAttribute("username") != null) {
String username = (String) session.getAttribute("username");
model.addAttribute("username", username);
return "home";
} else {
return "redirect:/login";
}
}
登出请求处理示例
@PostMapping("/logout")
public String logout(HttpServletRequest request) {
HttpSession session = request.getSession(false);
if (session != null) {
session.invalidate();
}
return "redirect:/login";
}
3. Session管理
创建和管理Session
创建Session:
- 使用
request.getSession(true)来创建一个新的会话或返回现有会话。
- 使用
存储和获取数据:
- 使用
session.setAttribute("key", value)来存储数据。 - 使用
session.getAttribute("key")来获取数据。
- 使用
使Session失效:
- 使用
session.invalidate()来使会话失效并清除所有与会话相关的数据。
- 使用
设置Session超时
- 可以在
web.xml中配置Session的超时时间,以控制会话的生命周期:
<session-config>
<session-timeout>30</session-timeout>
</session-config>
4. 安全性管理
HTTPS加密
- 使用HTTPS协议加密传输,保护Session ID在传输过程中不被窃取。
防止跨站请求伪造(CSRF)
- 使用CSRF令牌来确保请求的合法性,防止恶意网站伪造请求。
SameSite属性
通过设置Cookie的SameSite属性,防止跨站点请求携带Session ID:
//手动设置一个硬盘存储Cookie,这个Cookie是存在硬盘的,不是存在浏览器线程的 Cookie cookie = new Cookie("JSESSIONID", session.getId()); cookie.setHttpOnly(true); cookie.setSecure(true); cookie.setMaxAge(30 * 60); // 设置过期时间 cookie.setPath("/"); cookie.setDomain("example.com"); cookie.setSameSite("Strict"); // 或 "Lax" response.addCookie(cookie);自定义
key//Cookie的一些基本设置 Cookie cookie = new Cookie("Admin-Token", token); Cookie[] cookie2 = request.getCookies(); //request.getContextPath() mdrwebrest cookie.setPath("/"); //设置cookies有效路径 //设置cookie有效时间 正数:存到硬盘,负数存到浏览器,0立刻销毁 cookie.setMaxAge(); cookie.setDomain(loginToMDRConfig.getIP()); //跨域 response.addCookie(cookie);
优缺点
优点:
- 简单易用: 服务器端集中管理用户状态。
- 安全性高: 服务器端存储Session数据,不易被篡改。
- 自动处理: 大多数Web框架和服务器自动处理Session管理,开发者只需关注业务逻辑。
缺点:
- 扩展性问题: 在分布式系统中,需要实现Session共享(如使用Redis等)。
- 服务器资源占用: 每个Session会占用服务器内存,可能影响性能。
总结
Session认证机制通过在服务器端维护会话对象,实现了对用户身份的有效管理和认证。虽然在分布式环境中需要额外的措施来共享Session数据,但其简单和高效的特点使其成为Web应用中广泛使用的认证方式。
JWT认证机制
使用拦截器实现
参考代码:身份认证:Session/JWT - Gitee.com
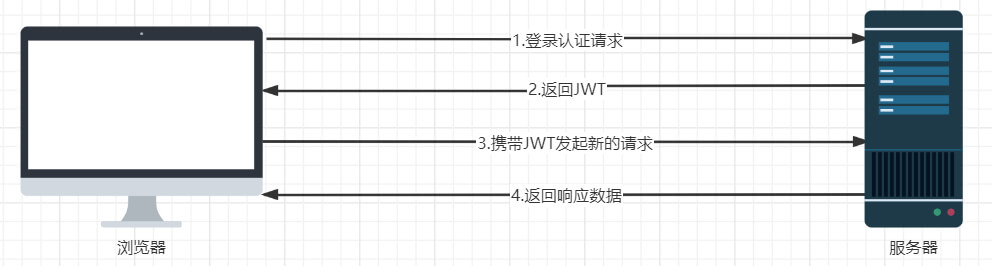
适用于分布式站点的单点登录(SSO)场景
W3C 的 HTTP 1.0 规范,Authorization 的格式是:
Authorization: <type> <authorization-parameters>
所以 Bearer 是授权的类型,常见的授权类型还有:
Basic :用于 http-basic 认证;
Bearer :常见于 OAuth 和 JWT 授权;
Digest MD5 :哈希的 http-basic 认证 (已弃用)
AWS4-HMAC-SHA256 AWS 授权
..
添加依赖
<!-- 0.12.x 版本语法发生了变化,详见代码仓库 -->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.12.5</version>
</dependency>
注意:JJWT依赖于Jackson 2.x.
Session Vs JWT
Session和Authorization 都是做web服务器之间登录验证的,因为http协议是无状态协议(对于服务器来说,没有老用户,每一次请求都是新请求)
- Session方式登录之后,在
Cookie中以JSESSIONID体现,请求会由浏览器自动带入 - JWT方式登录之后,需要手动在
Hearder中注入Authorization
权限验证
在Controller上使用自定义注解,如果开启了权限认证,那么则拦截该方法,并解析改用户是否具有这个Controller方法的权限
页面权限
表结构:用户 - (用户&角色) - 角色 - (角色&资源) - 资源
接口权限
(操作权限或按钮权限)
表结构:用户 - (用户&角色) - 角色 - (角色&权限) - 权限
示例:
在
@Aspect切面类定义里定义切点:如若依使用切入指定注解@annotation(com.ruoyi.common.security.annotation.RequiresPermissions)来验证本次登录用户的权限列表内是否拥有请求接口所需要的@RequiresPermissions("system:user:import")注解
数据权限
不同用户所能访问到的数据不同。
用户 <-> 角色 <-> 权限的包含关系图
用户 (User)
│
├── 小王 (User: 王)
│ └── 角色 (Role: 销售员)
│ ├── 权限 (Permission: 查看销售单据)
│ └── 权限 (Permission: 编辑销售单据)
│
├── 小李 (User: 李)
│ └── 角色 (Role: 财务管理员)
│ ├── 权限 (Permission: 查看财务单据)
│ ├── 权限 (Permission: 编辑财务单据)
│ └── 权限 (Permission: 审批财务单据)
│
└── 张经理 (User: 张)
└── 角色 (Role: 审计员)
└── 权限 (Permission: 查看所有部门单据)
硬编码,通过编写sql语句(不推荐)
ruoyi的处理方式
使用AOP切面,拦截指定方法:https://gitee.com/enlin-personal/aop-test
Mybatis拦截插件
提供了一个Interceptor接口,实现该接口定义一个拦截器对sql语句进行拦截达到数据过滤效果
logback
logback定义了8个级别的log(除去OFF和ALL,可以说分为6个级别),优先级从高到低依次为:OFF、FATAL、ERROR、WARN、INFO、DEBUG、TRACE、 ALL。
1、ALL 最低等级的,用于打开所有日志记录。
2、TRACE designates finer-grained informational events than the DEBUG.Since:1.2.12,很低的日志级别,一般不会使用。
3、DEBUG 指出细粒度信息事件对调试应用程序是非常有帮助的,主要用于开发过程中打印一些运行信息。
4、INFO 消息在粗粒度级别上突出强调应用程序的运行过程。打印一些你感兴趣的或者重要的信息,这个可以用于生产环境中输出程序运行的一些重要信息,但是不能滥用,避免打印过多的日志。
5、WARN 表明会出现潜在错误的情形,有些信息不是错误信息,但是也要给程序员的一些提示。
6、ERROR 指出虽然发生错误事件,但仍然不影响系统的继续运行。打印错误和异常信息,如果不想输出太多的日志,可以使用这个级别。
7、FATAL 指出每个严重的错误事件将会导致应用程序的退出。这个级别比较高了。重大错误,这种级别你可以直接停止程序了。
8、OFF 最高等级的,用于关闭所有日志记录。
注:如果将log level设置在某一个级别上,那么比此级别优先级高的log都能打印出来。例如,如果设置优先级为WARN,那么OFF、FATAL、ERROR、WARN 4个级别的log能正常输出,而INFO、DEBUG、TRACE、 ALL级别的log则会被忽略。Log4j建议只使用四个级别,优先级从高到低分别是ERROR、WARN、INFO、DEBUG。
从我们实验的结果可以看出,log4j默认的优先级为ERROR或者WARN(实际上是ERROR)。
异步编排
玩转CompletableFuture线程异步编排,看这一篇就够了 - l_v_y_forever - 博客园 (cnblogs.com)
Maven
下载:
环境变量:
MAVEN_HOME=D:\Maven\apache-maven-3.9.11- Path:
%MAVEN_HOME%\bin
配置镜像:https://developer.aliyun.com/mirror/maven
<mirror> <id>aliyunmaven</id> <mirrorOf>*</mirrorOf> <name>阿里云公共仓库</name> <url>https://maven.aliyun.com/repository/public</url> </mirror>