
pip
安装
pip install <package-name>[==x.xx]
# ./requirements.txt
pip install -r requirements.txt
# ./setup.py
pip install -e .
换源
pip config set global.index-url https://mirrors.huaweicloud.com/repository/pypi/simple
pip config set global.trusted-host mirrors.huaweicloud.com
警告
当python版本过高的时候,清华源可能会导致pip 下载包失败 ,可以临时更换为官方源以解决问题。
镜像源列表
# 使用官方 PyPI 源
pip install <package-name> --index-url https://pypi.org/simple/
## 以下是单次下载时拼接在 pip install <package-name> 里使用
# 华为云镜像源
-i https://mirrors.huaweicloud.com/repository/pypi/simple
# 阿里云镜像源 (推荐)
-i https://mirrors.aliyun.com/pypi/simple/
# 豆瓣镜像源
-i https://pypi.douban.com/simple/
# 中科大镜像源
-i https://pypi.mirrors.ustc.edu.cn/simple/
# 腾讯云镜像源
-i https://mirrors.cloud.tencent.com/pypi/simple/
# 清华源(移动网络最好不要用)
-i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
命令
# 列举当前环境安装的所有包
pip list
# 查看当前环境中的某个包信息
pip show <package-name>
# 从当前环境卸载某个包
pip uninstall <package-name>
# 查看当前 pip 配置; -v 从上到下依次加载,后面覆盖前面的
pip config list [-v]
conda
多环境
安装
环境变量
安装目录 & 安装目录/Scripts 添加到 Path 内
配置
修改pip源
pip config set global.index-url --site https://pypi.tuna.tsinghua.edu.cn/simple配置信息会被写到
D:\Program Files\miniconda3\pip.ini中。修改pip包安装路径
pip config set global.target "D:\Program Files\miniconda3\Lib\site-packages"查看 pip.ini 位置
pip -v config list查看当前 pip 包安装位置
pip show pip删除配置信息
pip config --user unset site.index-url pip config --user globalsite.index-url
使用
创建环境
# Replace <ENV_NAME> 环境名称
# Replace <PACKAGE> 需要安装的包(多个包使用空格分割)
# Replace <VERSION> 需要安装的包的版本(可选)
conda create --name <ENV_NAME> <PACKAGE>=<VERSION>
#示例
conda create -n py311 python=3.11
查看所有环境
conda info --envs
# 或
conda env list
切换到指定环境
# 若不填写环境名称,则使用base环境,也就是安装时自带的环境
conda activate <ENV_NAME>
# 如果首次使用是提示 `CondaError: Run 'conda init' before 'conda activate'`
# 先关闭所有 `CMD` 窗口,重新打开一个新的CMD窗口
conda init --system --all
取消激活环境
conda deactivate <ENV_NAME>
删除指定环境
conda env remove -n <ENV_NAME>
安装某个包
# 如果已经存在,则升级/降级
conda install python=3.11
study🥶
对比表格
| 名称 | 描述 | 新增 | 获取 | 修改 | 删除 | 备注 |
|---|---|---|---|---|---|---|
| list | 元素插入有序、可重复、可变列表 | 指定位置插入:list.insert(1, '元素') 追加:list.append('元素') | 第一个:list[0] 倒数第二个list[-2] | list[0]='修改' | 删除最后一个list.pop() 删除指定位置:list.pop(3) | 元素可以是任意类型 |
| tuple | 元素无序、可重复、不可变列表 | NULL | 同list | NULL | NULL | 元素可以是任意类型 |
| dict | 键值对 | dict['name'] = 'Enlin' | 没有key会报错:dict['name'] 没有key返回None:dict.get('age') 没有key返回自定义值:dict.get('age', -1) | dict['name'] = 'Enlin1' dict.update({'name': 'Enlin1'}) book_dict.update(name = 'Enlin1') 更多参照:dict | dict.pop('name') | 新增和修改的方法都是:不存在就新增,存在就修改 |
| set | 和dict类似,不过不存储value,(插入顺序)无序集合(无法通过下标获取元素) | set.add('Enlin') 将五个字母拆分之后add到原集合:set.update('Enlin') | for in 和 enumerate() 更多参照:set | NULL | set.remove('Enlin') | 元素不能为[]或{}等hash值会改变的对象,但可以放入结构后的值:*[]、*{} |
深拷贝
Python 直接赋值、浅拷贝和深度拷贝解析 | 菜鸟教程 (runoob.com)
这四个类型均可以使用
copy模块进行深拷贝import copy list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] tuple1 = tuple(list1) dict1 = {'name': 'Enlin', 'age': 18, 'sex': 'M'} set1 = {*[2, 3, 4, 5], 'e', 'b', *dict1} list2 = copy.deepcopy(list1) # 此处修改 list1,不再对 list2 有影响 for item in list1: print(item) tuple2 = copy.deepcopy(tuple1) # 此处修改 tuple1,不再对 tuple2 有影响 for item in tuple2: print(item) set2 = copy.deepcopy(set1) # 此处修改 set1,不再对 set2 有影响 for item in set2: print(item) dict2 = copy.deepcopy(dict1) # 此处修改 dict1,不再对 dict2 有影响 for key, value in dict2.items(): print(key, value)
list[] 列表
定义
// 使用方括号 [] 定义,元素之间用逗号分隔,元素可不同类型 list1 = [ 1,2,'3', [4.1, 4.2], 5, {'a': a, 'b': b}]遍历
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]for in
for i in list1: print(i)enumerate
for index, item in enumerate(list1): print(index, item)range(0, len(list))[1]
for i in range(0, len(list1)): print(list1[i]) # range 第三个参数 步进:2,详情看脚注解释 for i in range(0, len(list1), 2): print(list1[i])倒序遍历
# 简便方法 for i in reversed(list1): print(i) # 通用方法 for i in range(len(list1)-1, -1, -1): print(list1[i])使用分片
slicefor i in list1[::-1]: print(i)
sort()
给list排序(数学意义上的排序)
list.sort()
tuple() 元组
定义
// 使用方括号 [] 定义,元素之间用逗号分隔,元素可不同类型 tuple1 = (1,2,'3', [4.1, 4.2], 5, {'a': a, 'b': b})如果要定义一个空的tuple,可以写成
():>>> t = () >>> t ()
但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1
定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
实际上是,而不是()组成了元组。括号是可选的,除非在空元组的情况下https://docs.python.org/3/library/stdtypes.html#tuples
Note that it is actually the comma which makes a tuple, not the parentheses.The parentheses are optional, except in the empty tuple case, orwhen they are needed to avoid syntactic ambiguity.
dict{} 字典
定义
>>> dict1 = {'name': 'Enlin', 'age': 18, 'sex': 'M'} >>> dict1['name'] 'Enlin'dict的key必须是不可变对象。
第一种方式:使用[]
book_dict["owner"] = "tyson"说明:中括号指定key,赋值一个value,key不存在,则是添加元素(如果key已存在,则是修改key对应的value)
第二种方式:使用update()方法,参数为字典对象
book_dict.update({"country": "china"})说明:使用dict的update()方法,为其传入一个新的dict对象,key不存在则是添加元素!(如果这个新的dict对象中的key已经在当前的字典对象中存在了,则会覆盖掉key对应的value)
第三种方式:使用update()方法,参数为关键字参数
book_dict.update(temp = "无语中", help = "帮助")说明:同样使用dict的update方法,但传入的是关键字参数,key不存在则是添加元素(key存在则是修改value)
注意:关键字参数形式,key对象只能是字符串对象
第四种方式:使用update()方法,参数为字典解包方式
my_temp_dict = {"name": "王员外", "age":18} book_dict.update(**my_temp_dict)等同于
book_dict.update(name="王员外",age=18)
遍历
for key, value in my_dict.items(): print(key, value)dict()函数list1 = ['name', 'age', 'gender', 'address'] list2 = ['Enlin', 18, 'M', 'China'] dict_obj = dict(zip(list1, list2))zip()函数zip(list1, list2)函数将两个列表并行迭代,生成一个迭代器,每次迭代返回一个元组,元组的key来自list1,value来自list2。具体来说,zip()函数会将list1和list2中的对应元素打包成元组:zip_obj = zip(list1, list2) print(list(zip_obj)) # 输出:[('name', 'Enlin'), ('age', 18), ('gender', 'M'), ('address', 'China')]dict()函数dict()函数将由zip()返回的元组序列转换为字典。在这里,zip(list1, list2)返回的迭代器中的每个元组(key, value)会成为字典中的一个键值对:my_dict = dict(zip(list1, list2)) print(my_dict) # 输出:{'name': 'Enlin', 'age': 18, 'gender': 'M', 'address': 'China'}
set{} 集合
定义
set1 = {1, 3, 'a', 2, 'c'} # 或 list1 = [1, 3, 'a', 2, 'c'] set1 = {*list1, 2, 'b', 0}add和update# 使用字符串初始化集合 s1=set('liujingjing') print(s1) # {'g', 'i', 'j', 'l', 'n', 'u'} s1.add('oop') print(s1) # {'j', 'i', 'oop', 'n', 'l', 'g', 'u'} # update是将字符串中的拆分成字符进行追加 s1.update('oop') print(s1) # {'oop', 'i', 'l', 'j', 'o', 'n', 'g', 'u', 'p'}set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3]) >>> s2 = set([2, 3, 4]) >>> s1 & s2 {2, 3} >>> s1 | s2 {1, 2, 3, 4}遍历
set无序,不能用下标取值
for in
for item in set1: print(item)enumerate
for index, item in enumerate(set1): print(index, item)
运算
交集运算 取两集合公共的元素
运算符位:
&set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print(set1 & set2) # {4, 5}并集运算 取两集合全部的元素
运算符位:
|set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8}差集运算 取一个集合(被减数集合)中另一个集合没有的元素
运算符位:
-set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print('set1 - set2 =', set1 - set2) # set1 - set2 = {1, 2, 3} print('set2 - set1 =', set2 - set1) # set2 - set1 = {8, 6, 7}对称差集运算 取集合 A 和 B 中不属于
A&B的元素运算符位:
^set1 = {1, 2, 3, 4, 5} set2 = {4, 5, 6, 7, 8} print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
package
http.server
python3自带:快速创建文件服务器
# 启动 某个文件夹下
python -m http.server 2333
--bind 0.0.0.0:局域网内设备可访问。
注意
命令行直接启动这个库时,播放视频默认不支持Range(拖动进度条)。
- 可以使用 这个仓库里的文件 ,然后使用
python xxx.py命令启动。
视频文件较小是可以使用此替代方案:如果需要可以使用 Node 中的 http-server 库来实现。
uploadserver
快速创建 支持上传 的文件服务器
# 安装
pip install uploadserver
# 运行(支持上传和下载)
python -m uploadserver
# 指定端口
python -m uploadserver 2333
# 启用HTTPS
python -m uploadserver 2333 --cert certificate.pem --key key.pem
pyftpdlib
快速创建 ftp 服务器
# 安装
pip install pyftpdlib
# 启动
python -m pyftpdlib -p 21 -u enlin -P 123456 -w
可选参数
-i指定IP地址(默认为本机的IP地址)-p指定端口(默认为2121)-w写权限(默认为只读)-d指定目录 (默认为当前目录)-u指定用户名登录-P设置登录密码
pyinstaller
命令:
pyinstaller --onefile --noconsole --add-data "mars.png;." --add-data "data_mars.json;." notify_timer.py
提示
如果加了python相关环境变量之后还是提示“不是内部或外部命令...”,就使用
python -m PyInstaller [--onefile]
--onefile: 打包成exe单文件--noconsole: 隐藏cmd窗口(也可以写--windowded)--console: 显示cmd窗口(可以显示日志)
--add-data: "源路径;目标路径",上面的代表文件在根目录下的mars.png文件,根目录为.这是上述命令的目录结构
临时目录/ (sys._MEIPASS) ├── mars.png ├── data_mars.json ├── python38.dll └── 其他库文件...这是文件在子目录的方式
临时目录/ (sys._MEIPASS) ├── data/ │ ├── mars.png │ └── data_mars.json ├── python38.dll └── 其他库文件...命令即为:
--add-data "mars.png;resources",代码也需要同步修改;get_resource_path("resources/data_mars.json")
文件目录:
# 使用 pyinstaller,需要将图片和json文件打包到exe文件中
def get_resource_path(relative_path):
"""获取资源的绝对路径,兼容开发环境和打包后环境"""
# pyinstaller 打包的检测机制 判断程序是否运行在打包后的环境中 (sys._MEIPASS 临时解压目录)
if hasattr(sys, '_MEIPASS'):
# 打包后的临时解压目录
base_path = sys._MEIPASS
else:
# 开发环境
base_path = os.path.dirname(__file__)
return os.path.join(base_path, relative_path)
# 使用新的路径获取函数
img_url = get_resource_path("mars.png")
data_file = get_resource_path("data_mars.json")
批量处理文件名
遍历文件
import os
file_path = r".\moive"
for root, dirs, files in os.walk(file_path):
for file_name in files:
print(file_name)
获取文件后缀
os.path.splitext(file_name)[1]
寻找某个字符的位置
file_name.find('_')
重命名文件
os.rename(root + '/' + file_name, root + '/' + new_name)
# or os.rename(root + '\\' + file_name, root + '\\' + new_name)
项目
| name | url | ramarks |
|---|---|---|
| AnimatedDrawings | https://github.com/facebookresearch/AnimatedDrawings.git | 使明显正面站立人物的图片动起来 |
| biliLiveNotification | https://github.com/yunhuanyx/biliLiveNotification.git | bilibili直播通知 |
全局变量
C_INDEX = 0
def main():
# 取随机值,范围:[0, 9]
# 必须使用 `global` 重新声明一下,否则视为函数内定义了一个函数内作用域变量
global C_INDEX
C_INDEX = random.randint(0, 9)
if __name__ == "__main__":
main()
提示
基本数据类型需要修改全局变量,一定要使用
global重新声明。对象类型视情况而定,如果不给对象整体赋值(修改内存指向),就不用使用
global重新声明,因为只是修改对象属性,或者改变数组中元素值,并不会改变内存指向。不会被视为定义了一个新的函数内作用域对象。
语法🥵
函数和方法
- 函数是独立的代码块,可以在任何地方定义和调用。
- 方法是定义在类内部的函数,分为实例方法、类方法和静态方法,分别绑定到实例、类或不绑定任何对象。
- 方法在类中定义,因此它们依赖于该类。
源码
在 Python 中,方法定义中的 (self, *args, **kwargs) 是常见的函数签名格式,具有以下含义:
self:
self是 Python 中类实例方法的第一个参数。- 当类的实例调用方法时,Python 会自动将实例作为
self参数传递给方法,用于访问实例的属性和方法。 self参数允许方法在执行时访问和操作其所属的实例对象。
args:
*args是用来接收任意数量的位置参数(positional arguments)的元组。- 在方法定义中,
*args表示可以接受任意数量的额外位置参数,这些参数会被打包成一个元组传递给方法。 - 使用
*args可以处理不确定数量的位置参数,使方法更加灵活。
kwargs:
**kwargs是用来接收任意数量的关键字参数(keyword arguments)的字典。- 在方法定义中,
**kwargs表示可以接受任意数量的额外关键字参数,这些参数会被打包成一个字典传递给方法。 - 使用
**kwargs可以处理不确定数量的关键字参数,使方法更加通用和适应性强。
示例说明
以下是一个简单的类和方法定义,展示了 self, *args, **kwargs 的使用:
class MyClass:
def __init__(self, name):
self.name = name
def say_hello(self, *args, **kwargs):
print(f"Hello, I am {self.name}")
if args:
print("Additional positional arguments:")
for arg in args:
print(arg)
if kwargs:
print("Additional keyword arguments:")
for key, value in kwargs.items():
print(f"{key} = {value}")
# 创建类的实例
obj = MyClass("Enlin")
# 调用方法,使用 *args 和 **kwargs
obj.say_hello("Nice to meet you!", age=18, city="Beijing")
输出结果:
Hello, I am Enlin
Additional positional arguments:
Nice to meet you!
Additional keyword arguments:
age = 18
city = Beijing
在这个例子中:
self参数在say_hello方法中使用,用于访问实例变量self.name。*args接收了额外的位置参数"Nice to meet you!"。**kwargs接收了额外的关键字参数age=30和city="Wonderland"。
这种方法签名的设计使得方法可以灵活地处理不同数量和类型的参数,增强了方法的通用性和适应性。
class
使用 class 是面向对象编程(Object-Oriented Programming, OOP)的核心概念之一,它能够带来很多好处和灵活性。让我们逐步来理解使用 class 的好处以及一些相关的注意点和概念:
好处:
封装性:
class允许将数据(属性)和操作数据的方法(方法)组合在一起。- 这种封装性使得代码更易于维护和理解,可以隐藏内部复杂性,提供简单的接口供外部使用。
代码重用:
- 类可以通过继承机制派生出子类,子类可以重用父类的属性和方法。
- 这样可以减少代码重复,提高代码的可复用性。
可扩展性:
- 类的设计可以通过继承、多态等方式进行扩展和定制,使得程序更易于扩展和修改。
抽象和模块化:
- 类的设计可以帮助抽象出现实世界的对象和概念,使程序更贴近问题领域的语义。
- 可以将程序分解为相互独立的模块,提高代码的组织性和可维护性。
注意点和相关概念:
类常量:
- 类常量是指在类内部定义的不可变的常量,通常用大写字母命名。
- 它们在类的所有实例之间共享,可以通过类名直接访问。
class MyClass: MAX_COUNT = 100 print(MyClass.MAX_COUNT) # 输出:100类方法:
- 类方法使用装饰器
@classmethod定义,第一个参数通常命名为cls,表示类本身。 - 类方法可以访问类变量和其他类方法,但不能访问实例变量。
class MyClass: @classmethod def class_method(cls): print("This is a class method") MyClass.class_method() # 调用类方法- 类方法使用装饰器
私有方法和属性:
- 在Python中,通过在方法名或属性名前加上双下划线
__可以定义私有方法和私有属性。 - 私有方法和属性只能在类的内部访问,不能从外部直接访问。
class MyClass: def __init__(self): self.__private_var = 10 # 私有属性 def __private_method(self): print("This is a private method") def public_method(self): self.__private_method() # 内部调用私有方法 obj = MyClass() obj.public_method() # 可以调用公有方法间接调用私有方法- 在Python中,通过在方法名或属性名前加上双下划线
继承和多态:
- 继承允许一个类派生出一个子类,子类可以继承父类的属性和方法,并且可以重写父类的方法以实现多态。
class Animal: def sound(self): pass class Dog(Animal): def sound(self): print("Woof") class Cat(Animal): def sound(self): print("Meow") def make_sound(animal): animal.sound() dog = Dog() cat = Cat() make_sound(dog) # 输出:Woof make_sound(cat) # 输出:Meow类的实例化和使用:
- 类的实例化通过调用类名并传递必要的参数来完成。
- 实例化后的对象可以访问类的属性和方法,或者通过对象的特定操作来修改属性值。
class Car: def __init__(self, color, make): self.color = color self.make = make def display_info(self): print(f"Car color: {self.color}, Make: {self.make}") my_car = Car("Red", "Toyota") my_car.display_info() # 输出:Car color: Red, Make: Toyota
总结
使用 class 可以帮助更好地组织和管理代码,提高代码的重用性、可扩展性和可维护性。理解和掌握类的概念以及与之相关的特性和注意点,对于编写复杂的程序和解决实际问题非常重要。
slice
列表(list)中的 slice(切片)操作是一种从列表中获取子列表的方式。切片操作允许通过指定起始、结束和步长来获取列表的一部分,而不需要显式地遍历整个列表。
list[start:end:step]
- start:切片开始的索引(包括这个索引),默认为0。
- end:切片结束的索引(不包括这个索引),默认为列表的长度。
- step:切片的步长,默认为1。
示例
arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
基本切片 (获取子集)
print(arr[2:5]) # 输出: [2, 3, 4] (从索引2开始,到索引5结束,不包含5) print(arr[:4]) # 输出: [0, 1, 2, 3] (从头开始到索引4) print(arr[3:]) # 输出: [3, 4, 5, 6, 7, 8, 9] (从索引3到结尾) print(arr[:]) # 输出: [0, 1, 2, ..., 9] (复制整个列表)使用步长
print(arr[::2]) # 输出: [0, 2, 4, 6, 8] (每隔一个取一个) print(arr[1::2]) # 输出: [1, 3, 5, 7, 9] (从索引1开始,每隔一个取一个) print(arr[::3]) # 输出: [0, 3, 6, 9] (每隔两个取一个)负数索引 (从后往前)
Python 中
-1代表最后一个元素,-2代表倒数第二个,以此类推。print(arr[-3:]) # 输出: [7, 8, 9] (获取最后3个元素) print(arr[:-3]) # 输出: [0, 1, 2, 3, 4, 5, 6] (获取除了最后3个之外的所有元素) print(arr[-5:-2]) # 输出: [5, 6, 7] (从倒数第5个到倒数第2个)负步长 (反转序列)
print(arr[::-1]) # 输出: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] (完全反转) print(arr[5:1:-1])# 输出: [5, 4, 3, 2] (从索引5反向切片到索引2) print(arr[::-2]) # 输出: [9, 7, 5, 3, 1] (反转并跳步)切片赋值 (修改列表)
data = [0, 1, 2, 3, 4, 5] # 替换部分元素 data[1:3] = [9, 9] print(data) # 输出: [0, 9, 9, 3, 4, 5] # 插入元素 (切片长度为0时) data[2:2] = ['a', 'b'] print(data) # 输出: [0, 9, 'a', 'b', 9, 3, 4, 5] # 删除元素 (赋值为空列表) data[3:5] = [] print(data) # 输出: [0, 9, 'a', 3, 4, 5]
重要
- 左闭右开:切片包含
start索引,但不包含end索引。 - 不报错:如果
start或end超出了列表范围,Python 不会报错,而是只会返回存在的元素。arr[0:100]会返回整个列表。
- 浅拷贝:
arr[:]会创建一个列表的浅拷贝。修改新列表不会影响原列表(前提是列表里的元素是不可变对象,或者你只是替
换了元素引用)。
速查表
| 操作 | 语法 | 说明 |
|---|---|---|
| 取前 n 个 | arr[:n] | 索引 0 到 n-1 |
| 取后 n 个 | arr[-n:] | 倒数第 n 个到结尾 |
| 取中间一段 | arr[a:b] | 索引 a 到 b-1 |
| 每隔 k 个取 | arr[::k] | 步长为 k |
| 全部反转 | arr[::-1] | 步长为 -1 |
| 复制列表 | arr[:] | 创建新副本 |
copy
浅拷贝
a = {1: [1,2,3]} b = a.copy() # 其实和 `arr[:]` 底层实现一样 print(a, b) # 输出 ({1: [1, 2, 3]}, {1: [1, 2, 3]}) a[1].append(4) a, b print(a, b) # 输出 ({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]})深拷贝
import copy c = copy.deepcopy(a) print(a, c) # 输出 ({1: [1, 2, 3, 4]}, {1: [1, 2, 3, 4]}) a[1].append(5) print(a, c) # 输出 ({1: [1, 2, 3, 4, 5]}, {1: [1, 2, 3, 4]})
- b = a: 赋值引用,a 和 b 都指向同一个对象
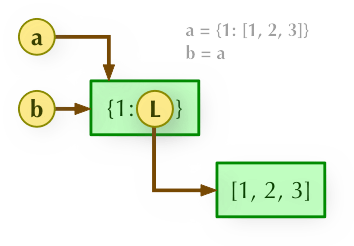
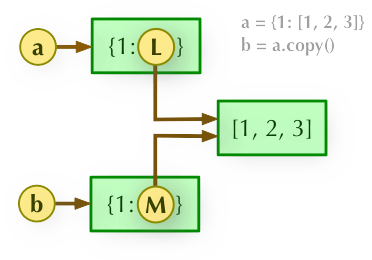
b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)
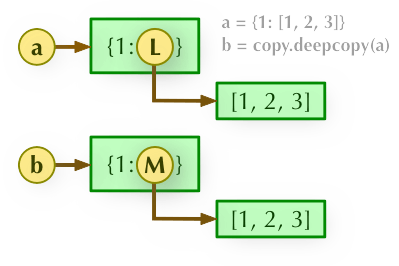
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的
以下实例是使用 copy 模块的 copy.copy( 浅拷贝 )和(copy.deepcopy ):
import copy
a = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = a #赋值,传对象的引用
c = copy.copy(a) #对象拷贝,浅拷贝
d = copy.deepcopy(a) #对象拷贝,深拷贝
a.append(5) #修改对象a
a[4].append('c') #修改对象a中的['a', 'b']数组对象
print( 'a = ', a ) # ('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])
print( 'b = ', b ) # ('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])
print( 'c = ', c ) # ('c = ', [1, 2, 3, 4, ['a', 'b', 'c']])
print( 'd = ', d ) # ('d = ', [1, 2, 3, 4, ['a', 'b']])
字符串
格式化:
# 位置参数
text = "{} + {} = {}"
result = text.format(2, 3, 5)
print(result) # 输出: 2 + 3 = 5
# 命名参数
text = "My name is {name}, I'm {age} years old"
result = text.format(name="Alice", age=25)
print(result) # 输出: My name is Alice, I'm 25 years old
# 数字格式化
text = "Price: ${:.2f}"
result = text.format(19.99)
print(result) # 输出: Price: $19.99
其他格式化方法:
f-string(推荐):
f"Hello, {name}!"name = 'Enlin' text = f'Hello, {name}!' # 'Hello, Enlin!'% 格式化:
"Hello, %s!" % "World"# %s 表示字符串占位符 text_template = 'Hello %s' result1 = text_template % 'Alice' print(result1) # 输出: Hello Alice result2 = text_template % 'Bob' print(result2) # 输出: Hello Bob # 多个参数 template = '%s is %d years old' result = template % ('Tom', 20) print(result) # 输出: Tom is 20 years old
连接字符串
在 Python 中,多个 字符串字面量 相邻放置时,会 自动连接 成一个字符串:
# 这三种写法完全等价:
text1 = "hello" "world"
text2 = ("hello" "world")
text3 = "helloworld"
print(text1 == text2 == text3) # 输出:True
这也就拓展到了以下知识点:
编辑器换行,字符串不换行(可以混用单双引号,甚至三引号)
text = ( "第一部分" "第二部分" "第三部分" ) print(text) # "第一部分第二部分第三部分"编辑器换行,字符串也换行,但编辑时没有显式键入'\n'
text = ''' 第一部分 第二部分 第三部分 ''' print(text) # '\n 第一部分\n 第二部分\n 第三部分\n' # 1. 可以看到换行后的空格也是被打印出来的 # 2. 字符串从三引号后就开始定义了,所以首尾也算换行,也会打印出换行符
常见问题
pip 下载错误
如果使用最新版 Python 版本进行 pip install 的时候,有可能会报错:
C:\Users\pc>pip install openai
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting openai
ERROR: HTTP error 403 while getting https://pypi.tuna.tsinghua.edu.cn/packages/55/4f/dbc0c124c40cb390508a82770fb9f6e3ed162560181a85089191a851c59a/openai-2.8.1-py3-none-any.whl (from https://pypi.tuna.tsinghua.edu.cn/simple/openai/) (requires-python:>=3.9)
C:\Users\pc>python -V
Python 3.13.9
这种错误是由于使用的 Python 版本太新,而清华镜像源可能还没有完全适配。可以临时切换 镜像源 。
名词释义😁
外部链接😒
循环一个给定的范围
range(a,b):包括a不包括b,形如[0,5),则遍历的是0, 1 , ..., 4;包含步长:
range(a,b,c):c为步长,形如range(0, 15, 2),则遍历的是0, 2 ,4, ..., 14↩︎